ReAct
ReAct: Synergizing Reasoning and Acting in Language Models
Introduction
In recent years, the development of large language models (LLMs) has significantly advanced natural language processing tasks. However, their performance in complex reasoning tasks such as question answering (QA) still presents challenges. To address this, the ReAct framework introduces a novel approach that combines few-shot prompting and Chain-of-Thought reasoning. By integrating external knowledge from sources like Wikipedia, ReAct enhances an LLM’s ability to reason and make informed decisions.
Research Gap
This paper is focusing on the ability of LLMs to effectively combine external information and internal reasoning for complex question-answering tasks. Prior to this work, there was a notable absence of approaches that integrated external knowledge extraction and internal reasoning mechanisms. The ReAct model attempts to bridge this gap by introducing a structured approach that interleaves action-based information retrieval with a CoT reasoning mechanism. This integration allows for a more sophisticated and context-aware decision-making process, enabling the model to dynamically determine when to rely on its internal knowledge and when to seek additional information from external sources, ultimately enhancing its overall performance in complex reasoning tasks.
Solution: ReAct
ReAct represents a few-shot-based approach designed to optimize the performance of LLMs through prompt-tuning, thereby harnessing both internal knowledge and external information. This technique enables the LLM to integrate reasoning and action when addressing various questions. Put simply, through the use of a few-shot prompt, the LLM learns to find out whether it possesses enough knowledge to answer a question or if it requires additional information. So, if it finds out that it requires more information, then it can obtain this information by calling different actions for evoking external knowledge bases, such as Wikipedia.
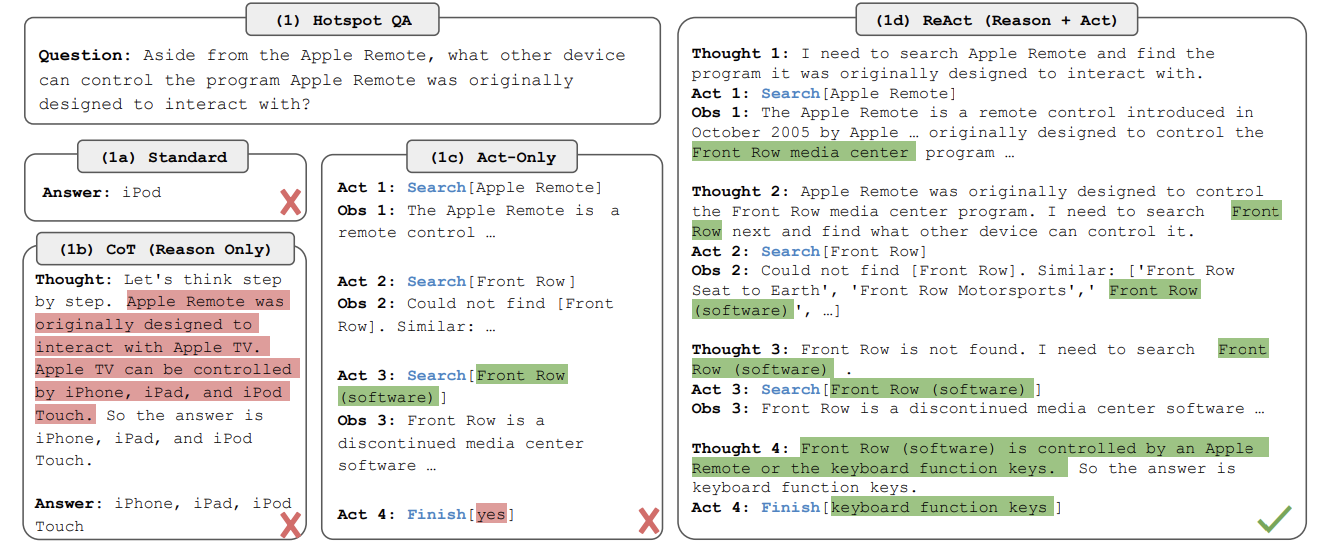
Delving deeper into the process, ReAct adopts a multi-step approach, similar to the CoT mechanism, to tackle complex tasks by breaking them down into simpler subtasks. By dividing the overall task into smaller and more manageable components, ReAct enables the LLM to address the complex challenge gradually. Each step in the ReAct process encompasses three key elements: thought (reasoning), action, and observation.
During the thought phase, the LLM employs its internal reasoning and existing knowledge to determine the appropriate course of action. Subsequently, the action phase entails the execution of the action determined during the thought process. These actions might involve: (1) searching Wikipedia for specific information, (2) looking up documents for specific keywords, or (3) concluding the task by providing an answer based on the extracted information thus far. Finally, the observation phase involves extracting the output generated by the action and integrating it with the existing reasoning and internal knowledge. This integration allows ReAct to evaluate the relevance and significance of the acquired information in the context of the overall question or problem at hand.
The following figure can provide an insight about how ReAct can change the reasoning process in previous works to achieve better results:
Experiments
The ReAct model is evaluated on various question-answering tasks, including both synthetic and real-world datasets.
For evaluation metrics, they leveraged standard measures such as accuracy, precision, recall, and F1 score to quantify the model’s performance on the QA task.
Additionally, the experiments include comparisons against several baseline models, including traditional language models and other state-of-the-art systems in the field of question-answering.
The results showcase the significant performance improvements achieved by ReAct compared to the baseline models across all the evaluation metrics. Notably, the model demonstrates enhanced reasoning capabilities and a more effective utilization of external knowledge sources, leading to improved accuracy and a higher F1 score in comparison to the baselines.
Conclusion
The ReAct framework represents a significant advancement in the field of natural language processing by effectively combining few-shot prompting and Chain-of-Thought reasoning. By leveraging internal and external knowledge, ReAct demonstrates promising results in enhancing the performance of LLMs for complex reasoning tasks. Its multi-step approach, involving thoughtful reasoning, action-taking, and observation, showcases the potential for future developments in the realm of intelligent systems.