Paper Review - Week 11
Several interesting papers are published in this week in NLP. Here is a list of them:
CoLT5: Faster Long-range Transformers with Conditional Computation
This paper focuses on the scalability problem of computing attentions in transformer-based architectures. Such scalability problem especially appears while processing long documents with a transformer-based models; the reason is that:
- A main component of the transformer architecture is the attention module. However, the attention computational cost scales quadratically with input length.
- The feedforward network and the projection layer in the transformer architecture should be applied on all of the input tokens.
CoLT5 is an extension to LongT5, which tries to solve the mentioned challenge. The main objective of CoLT5 is to reduce the computation burden in both the training phase and inference phase in the transformer-based architectures. The main idea of CoLT5 is to divide the transformer components into two branches: light branch–which is applied to all of the tokens in the input, and the heavy-branch–which is only applied to a selected list of input tokens.
The architecture of CoLT5 is depicted in the following figure:
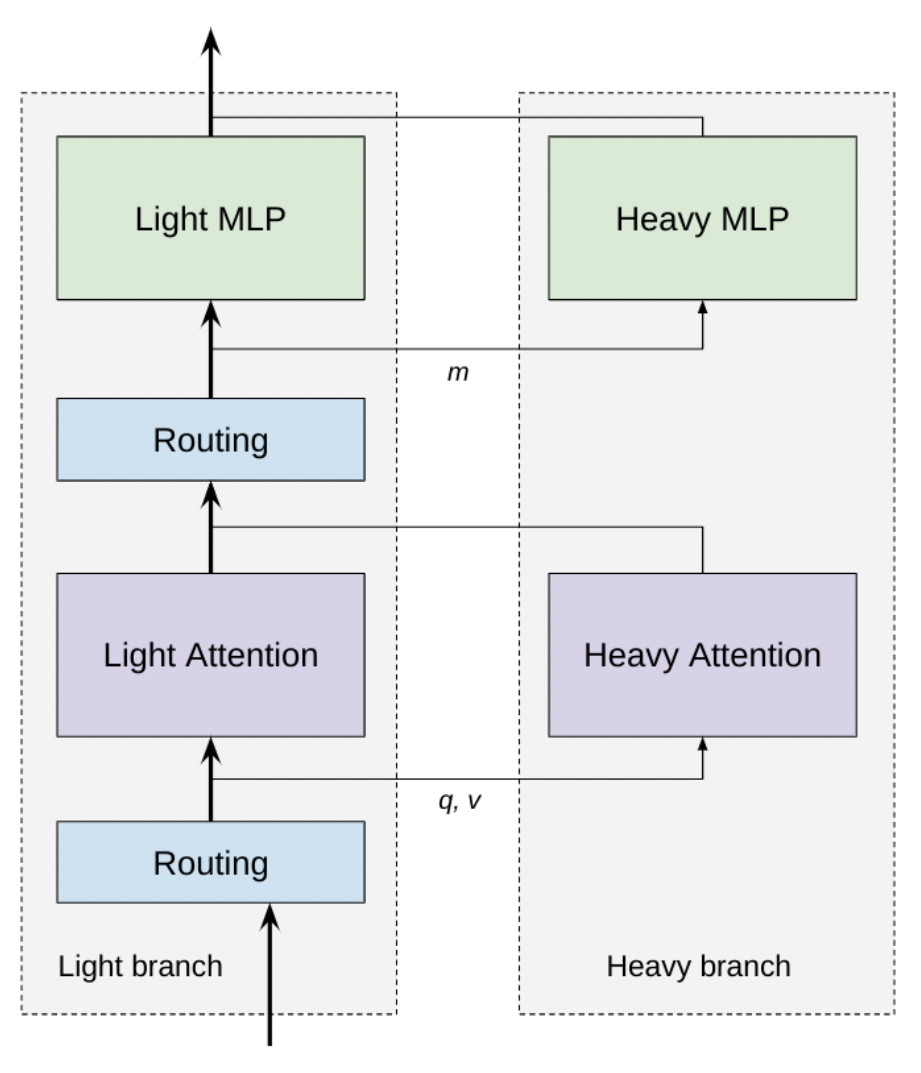
As is shown, one of the components of CoLT5 is the Routing component. Routing component is composed of two parts:
- a learnable vector which has the same dimentionality as the input. This vector is multiplied by all the input tokens, leading to having a score value for each of the tokens. So, it the input has n tokens, at this step, n score values are calculated.
- a function which recieves the score of all input tokens and select the top k input tokens with the highest score.
After the first routing component, input tokens are divided into two groups: the important and the non-important ones! The important ones (the ones with the highest score) will be passed to the heavy attention component. In this component, the full attention is applied to all of these tokens. Then, the less important ones are passed to the light attention component. In this component, for each token, the attention is applied only to a specific number of tokens surrounding it–its local context window. In other words, the difference between the light and heavy attention is that:
- The light attention has fewer head and attends only yo a local context window.
- The heavy attention has more heads and attends to all the important (highly-scored) tokens.
The idea behid leveraging this approach is that, for the more important tokens the long-range dependencies are worth to be counted. However, for the less important ones, only the short-range dependencies are worth counting.
After passing the tokens through the heavy and light attention components, the output of the attention components are used to calculate the new representations. For example, if \(s_i\) is the importance score of token \(i\) (which is set to 0 if token \(i\) is not among the top-\(k\) important tokens), then the new representation of token \(i\) is represented by \(X_i\), which is calculated as:
\[X_i = X_i + Att_{Light}(X_i) + s_i * Att_{Heavy}(X_i)\]Then, the newly-calculated representations are passed to another routing component to select the top-\(k\) important tokens. The most important ones are passed to a heavy feedforward network and the less important ones are passed to a light feedforward network. The difference between the light and heavy feedforward networks is only in their number of hidden layers. So, to calculate the final representation of the input tokens, considering \(s_i\) as the importance score of token \(i\), the following formula can be used:
\[X_i = X_i + FFN_{Light}(X_i) + s_i * FFN_{Heavy}(X_i)\]They used FLOP as the metric for measuring the computational cost of their approach. Their experiments show that they could achieve less computational cost compared to their baseline–LongT5.
Memorizing Transformers
The way that most of transformer-based langugae models work is that, first, they should be pretrained and finetuned; then, they can be used in different appications. During the runtime (the application phase), since the weights and model parameters are freezed, the models cannot learn anything new. So, this paper tries to solve this problem by adding an extenral memory for the transformer architecture.
Their idea is to add an external memory to some of the transformer layers. Then, in the augmented layers, instead of only computing the regular attention, they use another attention score in which the keys and values are calculated based on the external memory. So, for the augmented layer, they use a combination of these two attention scores. Their proposed architecture is depicted in the following figure:
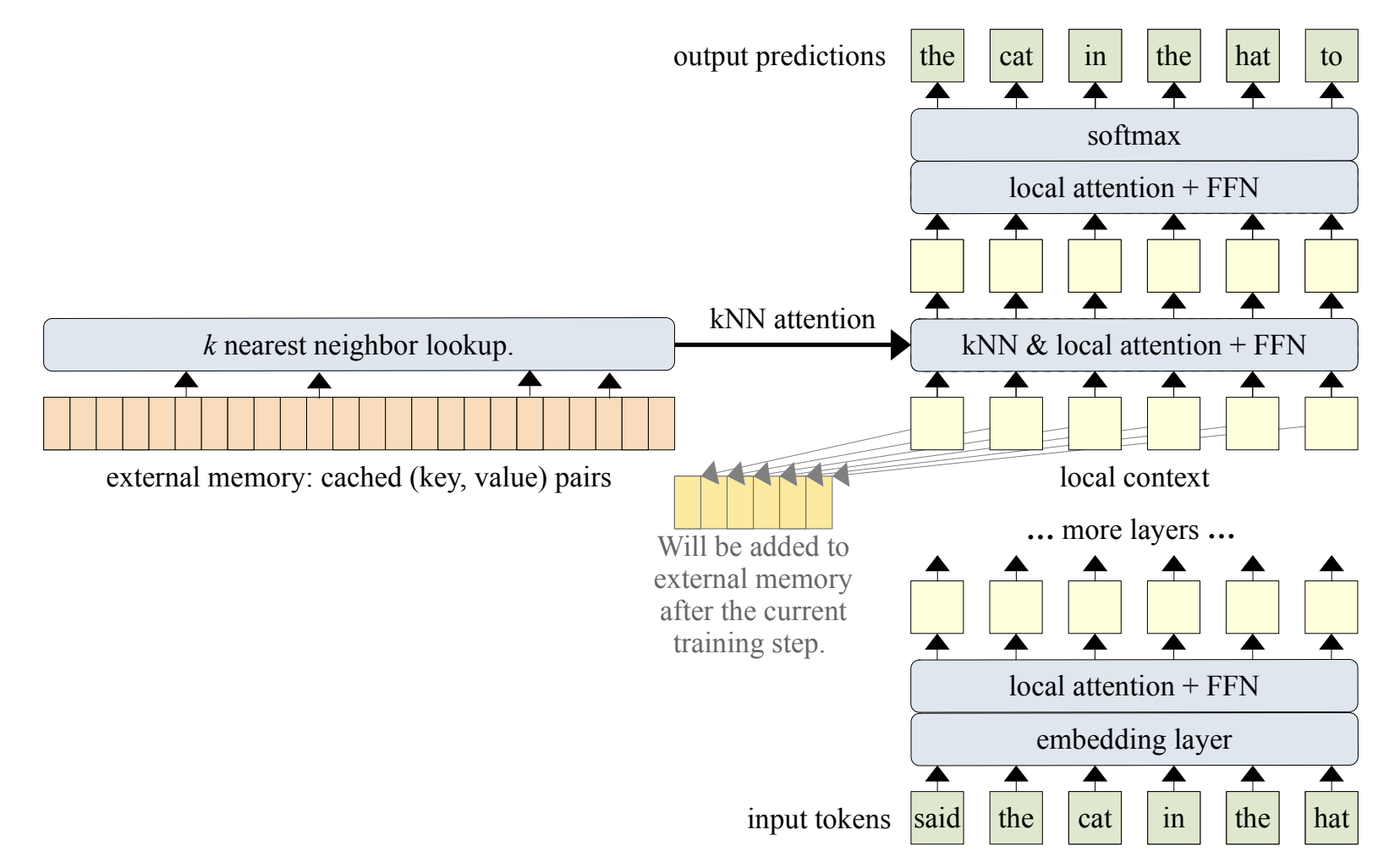
Let us describe the process in more details. \(W_k\), \(W_v\), and \(W_q\) are weight matrices for keys, values, and queries, respectively. The input text is \(X\) and the external memory in layer \(i\) is denoted by \(M\). Then, the regular attention is calculated as:
\[\begin{gather*} K = X \times W_k \\ V = X \times W_v \\ Q = X \times W_q \\ att_r = attention(K,V,Q) = softmax(\frac{QK^T}{\sqrt{d_k}})V \\ \end{gather*}\]Similarly, the attention from the external memory is calculated as:
\[\begin{gather*} K_m = M \times W_k \\ V = X \times W_v \\ Q = X \times W_q \\ att_m = attention(K_m,V,Q) = softmax(\frac{QK_m^T}{\sqrt{d_k}})V \\ \end{gather*}\]The final attention is then calculated as follows. Here, \(b\) is a per-head learnable vector.
\[\begin{gather*} ratio = sigmoid(b)\\ att_{final} = ratio \odot att_r + (1 - ratio) \odot att_m \end{gather*}\]They applied their idea on different transformer-based architecture. Their finding is that adding memory to such architectures can significantly improve the performance. Even, adding a small-size memory to a light-weight transformer-based architecture can result in better performance than using a larage and heavy transformer-based architecture with a lot of learnable parameters.
Here are some more articles relevant to this one: