Paper Review - Week 8
Several interesting papers are published in this week in NLP. Here is a list of them:
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Introduction
Large language models (LLMs) have shown remarkable progress across various natural language processing tasks, but they still face significant challenges such as generating inaccurate information, producing faulty code, and occasionally creating harmful or toxic content. Traditional methods to address these issues often involve extensive retraining or reliance on large-scale annotated datasets, which can be both resource-intensive and task-specific. This paper introduces the CRITIC framework, a novel approach that allows LLMs to iteratively improve their outputs by integrating feedback from external tools. By leveraging resources such as search engines, code interpreters, and toxicity detectors, CRITIC enables LLMs to refine their responses in a manner similar to how humans use external references to validate and correct their work. This method enhances the model’s reliability and versatility across a wide range of tasks without the need for additional training or annotations.
Research Gap
Existing methods for improving the performance of LLMs often rely on resource-intensive techniques like fine-tuning or RLHF, which may not generalize well across different tasks. The primary gap this work addresses is the need for a versatile, task-agnostic framework that enables LLMs to iteratively improve their outputs without extensive retraining. Unlike traditional approaches, the CRITIC framework introduces a novel method that incorporates external tools, such as search engines and code interpreters, to provide actionable feedback, which is then used to refine the model’s output in subsequent iterations. This approach significantly enhances the reliability and accuracy of LLMs across diverse tasks without the need for task-specific adjustments.
Difference Between CRITIC and Self-Refine While both CRITIC and Self-Refine aim to iteratively improve LLM outputs, they differ fundamentally in their approach. Self-Refine relies solely on the model’s internal feedback mechanisms to identify and correct errors, which can be limiting if the model’s initial reasoning is flawed. In contrast, CRITIC enhances this process by integrating external feedback from tools like search engines and code interpreters, providing more robust and reliable corrections. This external validation makes CRITIC more effective across a wider range of tasks, ensuring that the LLM’s improvements are grounded in accurate, externally verified information.
Solution: CRITIC
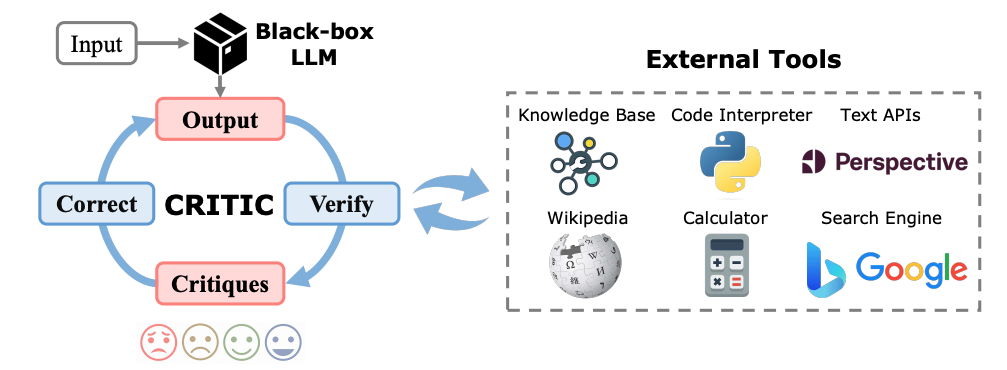
CRITIC (Correcting with Tool-Interactive Critiquing) is a framework designed to enable LLMs to iteratively improve their outputs by interacting with external tools. The method is based on the idea that LLMs, which often operate as “black boxes,” can enhance their output quality by receiving and incorporating feedback from external sources, similar to how humans refine their work.
Key Steps in the CRITIC Method:
- Initial Output Generation:
- The LLM first generates an initial output based on an input prompt using its internal parametric knowledge.
- This output is produced in a typical LLM fashion, without any external interaction at this stage.
- Verification with External Tools:
- After generating the initial output, the LLM interacts with one or more external tools to evaluate specific aspects of the output. These tools could include:
- Search Engines (e.g., Google) for fact-checking.
- Code Interpreters for verifying the correctness of generated code.
- Calculators for checking numerical accuracy.
- Toxicity Detectors (e.g., PERSPECTIVE API) for assessing the safety and appropriateness of the content.
- The tools return feedback, often in the form of critiques, which highlight issues like factual inaccuracies, logical errors, or harmful content.
- After generating the initial output, the LLM interacts with one or more external tools to evaluate specific aspects of the output. These tools could include:
- Integrating Critiques:
- The LLM doesn’t merely receive these critiques as isolated pieces of feedback. Instead, these critiques are integrated with the original input to form a new, enriched prompt.
- This new prompt typically consists of: - The original input or question. - The initial output generated by the LLM. - The critiques or feedback provided by the external tools.
- Correcting the Output:
- The LLM is then prompted with this enriched input (original input + critiques) to generate a revised output.
- This corrected output aims to address the issues identified in the critiques.
- Iterative Process:
- The “Verify → Correct” cycle can be repeated multiple times. In each iteration, the LLM generates a new output based on the latest critiques, and this output is again verified using the external tools.
- The process continues until the feedback indicates that the output meets the desired quality standards (e.g., factual accuracy, correctness, or reduced toxicity).
- Stopping Criteria:
- The iterative process can stop when one of the following conditions is met:
- The feedback from external tools suggests that the output is satisfactory.
- The maximum number of iterations is reached.
- The output remains unchanged across consecutive iterations, indicating convergence.
- The iterative process can stop when one of the following conditions is met:
The procedure and the psudo-code are depicted in the following two figures:

Advantages of the CRITIC Method:
- Enhanced Reliability: By incorporating external feedback, CRITIC addresses the limitations of LLMs in self-correcting their outputs, leading to more reliable results.
- Versatility: The method can be applied to various tasks (e.g., question answering, mathematical reasoning, toxicity reduction) without requiring task-specific retraining or extensive human annotations.
- Practicality: CRITIC utilizes in-context learning and text-to-text APIs, making it accessible and practical for a wide range of applications.
Experiments
The CRITIC framework was evaluated across three distinct tasks: free-form question answering, mathematical program synthesis, and toxicity reduction.
Free-Form Question Answering
Objective: To assess the truthfulness and accuracy of LLM-generated answers to open-ended questions.
- Datasets:
- AmbigNQ: An enhanced version of Natural Questions, focusing on ambiguous queries.
- TriviaQA: A large-scale question-answering dataset with questions and answers sourced from trivia games.
- HotpotQA: A dataset designed for multi-hop reasoning, where multiple pieces of evidence are needed to answer a question.
-
LLMs: Text-Davinci-003, ChatGPT, LLaMA-2
- Tools for Extracting Feedback:
- Google Search API: Used to fact-check the responses by querying the search engine and extracting relevant snippets from the top-ranked search results.
- Baselines:
- Vanilla Few-Shot Prompting: The LLM directly generates answers based on a few-shot prompt.
- Chain-of-Thought (CoT) Prompting: The LLM generates step-by-step reasoning before providing the final answer.
- Self-Consistency: Multiple outputs are generated, and the most consistent answer is selected.
- ReAct: A retrieval-augmented method where reasoning and retrieved knowledge are combined.
- Results:
- CRITIC significantly outperformed the baselines, showing marked improvements in F1 scores across AmbigNQ, TriviaQA, and HotpotQA datasets.
- CRITIC achieved substantial gains over the initial CoT results and surpassed the ReAct method by effectively combining intrinsic LLM knowledge with external feedback.
- The use of external tools was critical, as the model’s own critiques (CRITIC without tools) contributed marginally to the improvement.
Mathematical Program Synthesis
Objective: To evaluate the correctness and executability of programs generated by the LLM for solving mathematical problems.
- Datasets:
- GSM8k: A dataset focused on grade-school math word problems.
- SVAMP: A dataset for solving varied arithmetic math problems.
- TabMWP: A dataset that combines tabular data with word problems, requiring the model to synthesize and compute.
-
LLMs: Text-Davinci-003, ChatGPT, LLaMA-2-70B
- Tools for Extracting Feedback:
- Python Interpreter: Used to execute the generated programs and provide feedback in the form of error messages or execution results.
- Baselines:
- Vanilla Few-Shot Prompting: Direct program generation based on a few-shot prompt.
- Program-of-Thought (PoT): A method where the LLM writes programs to solve mathematical problems.
- Results:
- CRITIC showed notable improvements over the PoT baseline, particularly in the GSM8k, SVAMP, and TabMWP datasets.
- The CRITIC framework’s ability to incorporate interpreter feedback led to significant performance gains, especially when paired with larger LLMs.
- Removing the execution feedback (CRITIC without tools) led to reduced and unstable performance, highlighting the importance of external tool interaction.
Toxicity Reduction
Objective: To reduce the generation of toxic content while maintaining fluency and diversity in LLM outputs.
- Dataset:
- REALTOXICITYPROMPTS: A dataset designed to elicit potentially toxic responses from LLMs, used for evaluating the ability to generate non-toxic text.
-
LLMs: Text-Davinci-003, ChatGPT
- Tools for Extracting Feedback:
- PERSPECTIVE API: A tool for assessing the toxicity levels of generated text, providing scores for overall toxicity and specific toxic attributes (e.g., insult, profanity).
- Baselines:
- Learning Methods: Including PPLM, GeDi, DEXPERT, DAPT, PPO, and Quark, which use various reinforcement learning and controlled text generation techniques.
- Self-Correct: A method where LLMs iteratively reduce toxicity using self-feedback.
- Results:
- CRITIC substantially lowered the probability of generating toxic content while preserving the fluency and diversity of the output, outperforming many of the existing methods.
- The integration of external feedback from the PERSPECTIVE API proved crucial, as CRITIC without external tools showed less effective toxicity reduction.
- CRITIC’s performance in toxicity reduction was on par with supervised state-of-the-art methods, despite not requiring additional training data.
An example scenario of the framework is depicted in the following figure:

Conclusion
The CRITIC framework represents a significant advancement in the iterative improvement of LLM outputs by incorporating external tool-based feedback into the correction process. Unlike traditional self-correction methods that rely solely on the model’s internal mechanisms, CRITIC effectively combines the LLM’s intrinsic capabilities with external validation, resulting in more accurate and reliable outputs across various tasks such as question answering, mathematical reasoning, and toxicity reduction. The experimental results demonstrate that CRITIC outperforms existing methods by providing a practical, task-agnostic solution that does not require extensive retraining or additional data. This work paves the way for more robust and trustworthy AI systems, highlighting the importance of external feedback in the continuous self-improvement of language models.
Here are some more articles relevant to this one: