Paper Review - Week 18
Here is the list of the most interesting papers published in this week:
- Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
- Unlimiformer: Long-Range Transformers with Unlimited Length Input
- Learning to Reason and Memorize with Self-Notes
Distilling Step-by-Step!
With the recent significant increase in the size of language models, their scalability and affordablity is being constantly questioned. For example, serving a language models with the same size of GPT3 (175B parameters), which not even the largest existing language model, requires at least 350GB GPU memory. Accordingly, the focus of this paper is to find a way to train smaller language models with comparable performance to the extremely-large ones. So that, such smaller language models can be more scalable as well as affordable.
To train such small language models, there exist two common approach: (1) fintuning–training smaller language models using human-labeled and task-specific data; (2) distillation–training smaller language models using the labels generated by a larger language model.
In this paper, the authors proposed a specific distillation strategy in which smaller language models are taught how to do reasoning like the larger ones! Their general approach is that they leverage chain-of-thought (CoT) prompting to extract the rationales from the large lanuage models. Then, these extracted rationales are used as additional information along with the labeled data for training the smaller language models. So, in this approach, not only the labels, but also the rationales are distilled from the large language models to the smaller ones.
The detailed procedure can be described as follows:
- Let us say that there exist an unlabeled dataset like \(D\) which is for a specific task, such as question-answering and classification.
- We need to feed each item in \(D\), such as \(x_i\), to a large language model to extract output and rationale behind generation of that output. Let us say that a task-specific prompt template like \(p\) is used for this purpose.
- Then, \(x_i\) is appended to \(p\) and fed to the language model. The output of the language model is the task-specific output (e.g., lables for the classification tasks) and the rationale behind that. The task-specific output and the extracted rationale are represented by \(\hat{y}_i\) and \(\hat{r}_i\), respectively.
- By this step, for each item in the dataset, we have the output and rationale of a large language model which is supposed to be used for distilling a much smaller model.
- For training the smaller language model–also known as the student model, they authors proposed two distillation tasks:
- Label Prediction Task: In this task, the input item is
[LABEL]\(x_i\), and the output is represented by \(f(x_i)\). The loss function used for this task is the cross-entropy loss between the predicted and target tokens: \(L_{label} = {1 \over N} \sum_{i = 1}^{N} l(f(x_i), \hat{y}_i)\) - Rationale Generation Task: For rationale prediction, the same small language model is used for label prediction is used but with a different input and loss function. Here, the input item is
[RATIONALE]\(x_i\), the output is again represented by \(f(x_i)\). The loss function used for this task is the cross-entropy loss between the generated and target rationale: \(L_{rationale} = {1 \over N} \sum_{i = 1}^{N} l(f(x_i), \hat{r}_i)\)
- Label Prediction Task: In this task, the input item is
- Finally, for each item in the data, the weights of the small language model are updated using the following loss function: \(L = L_{label} + \lambda L_{rationale}\)
Using such inspiring design, they proposed language models which have over 500 \times less model parameters, but still achieves a performance which is comparable to that of the large ones. The general approach is depicted in the figure below:
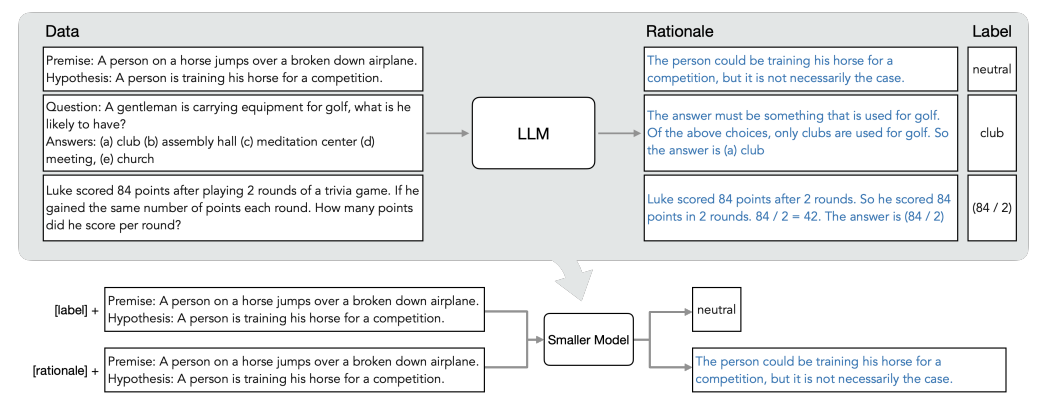
This work is a very interesting because of their creative use of CoT prompting for reducing the size of language models. However, one of the drawbacks of this approach is that in contrast to the existing LLMs, these models are task specific and don’t have the generalizing capability. Also, they claim that their approach is multi-modal; however, they have only conducted experiments on text-based applications.
Here are some more articles relevant to this one: