Paper Review - Week 27
Here is the list of the most interesting papers published in this week:
- GenRec: Large Language Model for Generative Recommendation
- Generative Job Recommendations with Large Language Model
GenRec: Large Language Model for Generative Recommendation
Introduction
In the rapidly evolving landscape of recommendation systems, the integration of large language models (LLMs) has emerged as a groundbreaking approach with significant potential. This paper introduces a model, GenRec, which leverages the power of LLMs for generative recommendation tasks. By directly generating target items based on comprehensive textual data understanding, GenRec demonstrates the potential of LLMs in revolutionizing the recommendation landscape.
Research Gap
The paper introduces the concept of generative recommendation, wherein the target item is directly generated, in contrast to traditional discriminative recommendation systems that calculate ranking scores for each candidate item. Therefore, they proposed GenRec model, which operates as an LLM-based system that leverages textual user interaction data to provide personalized item recommendations.
Personal Opinion: However, a notable limitation of the paper is the lack of comprehensive comparison with other existing LLM-based recommendation systems. While it compares GenRec with P5, which primarily operates based on user and item IDs, the paper falls short in providing a thorough analysis and comparison with other state-of-the-art LLM-based recommendation models that incorporate textual information. Also, since its focus is on generative recommendation task, it was better to mention the hallucination problem as well.
Solution: GenRec
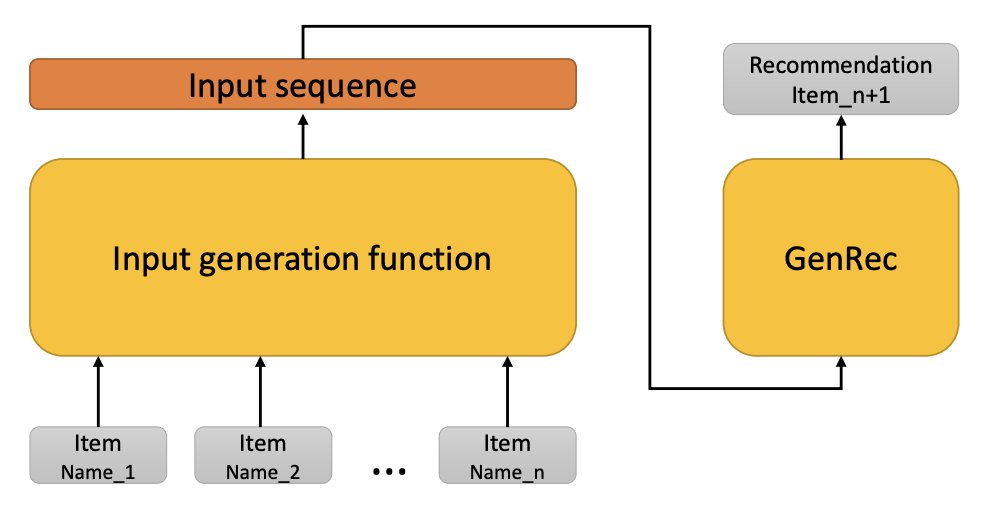
GenRec primarily leverages an LLM to generate the next recommended item based on a formatted prompt. This prompt consists of three parts:
-
Instruction: A fixed template for each recommendation task that provides specific guidance to the LLM regarding the nature and context of the recommendation task.
-
Input: Concatenation of the names of the items with which the user has previously interacted. This historical interaction data serves to provide context to the LLM, allowing it to understand the user’s preferences and behavior.
-
Output: A segment left for the LLM to complete, representing the predicted next item for the user to interact with. The LLM’s understanding of the user’s preferences and historical interactions enables it to generate informed recommendations for the user.
While the GenRec model utilizes the LLaMA large language model as its backbone, it is not limited to any specific LLM. This flexibility allows for the adaptation of the GenRec approach to various LLMs, depending on the specific requirements and context of the recommendation task at hand.
Here is a brief overview of the architecture of GenRec:
This is an example of the formatted prompt in GenRec:

Experiments
The experiments conducted in the paper aimed to evaluate the performance of the proposed recommendation system, GenRec, in sequential recommendation. The primary aspects of the experimental setup are outlined below:
- Datasets: The experiments were performed on two real-world datasets - the Amazon Toys dataset and the MovieLens-25M dataset.
- Baseline Methods: The paper compared the performance of the GenRec model with the P5 model, which operates based on user and item IDs.
- Evaluation Metrics: The evaluation metrics utilized are Hit Ratio (HR), Normalized Discounted Cumulative Gain (NDCG). Also, the core LLM used in GenRec is LLaMA.
- Results: While P5 showed better performance on the Amazon Toys dataset, the GenRec model exhibited significantly improved results on the MovieLens 25M dataset.
Conclusion
In conclusion, the GenRec model presents an LLM-based recommendation system. By effectively leveraging the rich contextual information embedded within LLMs, GenRec provides a reasonably accurate and personalized recommendations.
Generative Job Recommendations with Large Language Model
Introduction
In the ever-evolving landscape of job marketplaces, the need for efficient and accurate job recommendation systems has become paramount. Traditional approaches often rely on discriminative models that match job seekers with available positions based on predefined criteria. However, the growing complexity of user preferences and job requirements demands a more sophisticated and interactive approach. To address these challenges, they propose a novel framework called Generative Interactive Reinforcement Learning (GIRL) for job recommendation. GIRL leverages the power of large language models and reinforcement learning techniques to generate high-quality job descriptions and optimize recommendations based on user preferences, thereby enhancing the overall efficiency and effectiveness of the job recommendation process.
Research Gap
This paper addresses several critical gaps in the existing job recommendation systems. Some of these gaps include:
- Lack of Explainability: Many existing job recommendation systems operate as “black-box” models, meaning they lack transparency in how they provide recommendations. So, the authors address this problem by leveraging LLMs to generate job descriptions based on the candidates’ CVs. By utilizing LLMs, the system can offer detailed and coherent job recommendations that are easily understandable to the job seekers.
- Limitations of Traditional Models: Traditional job recommendation models often focus on collaborative filtering or person-job matching strategies. While these methods are effective to a certain extent, they are limited in their ability to offer comprehensive career guidance. To address this problem, instead of relying solely on collaborative filtering or person-job matching, they proposed a novel generative approach..
- Semantic Gap between CVs and JDs: The existence of a significant semantic gap between the information in candidates’ CVs and the requirements in JDs results in underwhelming performance for traditional methods. This gap makes it challenging to match job seekers with their ideal positions effectively. In this paper, by utilizing LLMs and the proposed training methodology, the GIRL framework effectively bridges the semantic gap between CVs and JDs.
Solution: GIRL
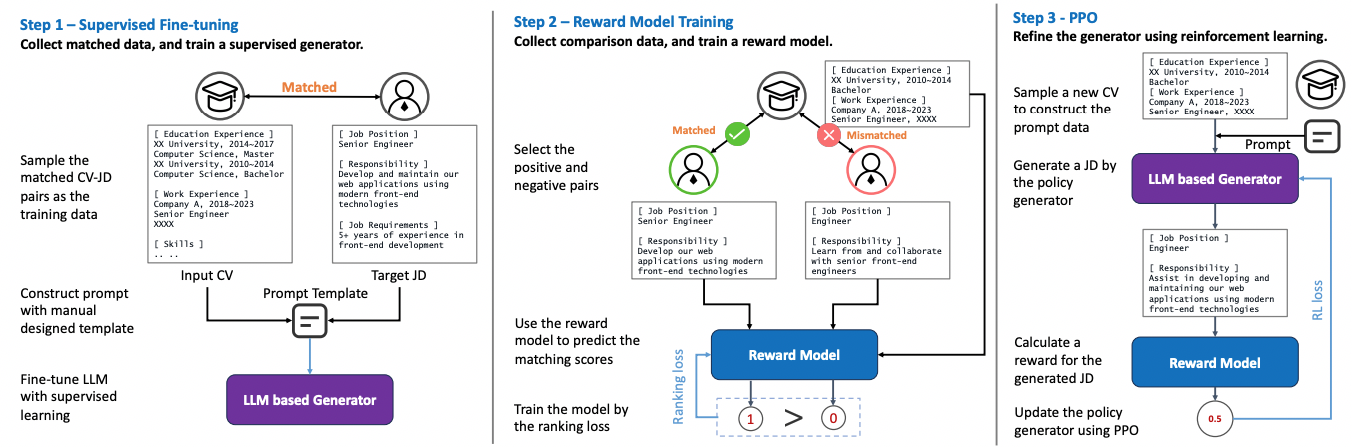
GIRL is composed of three steps. These steps are described as follows:
-
Supervised Fine-Tuning: In the first step, the aim is to train a LLM-based generative model based on supervised learning. Specifically, the model is trained to generate suitable Job Descriptions (JDs) based on the given Curriculum Vitae (CV) of a job seeker. The inputs to the generative model include the CV of the job seeker and a prompt template that describes the generation task using natural language. The output of the model is the generated Job Description (JD) that is tailored to the specific job seeker’s profile.Now let us clarify how this LLM-based generation model is trained and used in the inference time.During the training phase, the model is provided with pairs of CVs and their corresponding matched job descriptions. These pairs are used to create prompts that contain information from both the CV and the existing job description. The LLM-based generator is trained to generate job descriptions that align with the information provided in the prompts. The negative log likelihood serves as the loss function, which measures the dissimilarity between the generated job description and the one provided in the prompt. This loss function guides the training process, helping the model learn to generate more accurate and contextually relevant job descriptions.During the inference time, the trained model receives only the CV, which represents the job seeker’s profile, and it is expected to generate a suitable job description based on the learned patterns from the training data. This process ensures that the model can provide personalized and relevant job recommendations based solely on the input of the job seeker’s CV during real-world use.
-
Reward Model Training: In the second step of the GIRL framework, the main objective is to train a reward model that evaluates the matching degree between the CV and JD pairs. During the training phase, the reward model receives both positive pairs, where the CV and JD are a good match, and negative pairs, where the CV and JD do not match well. This information is used to train the reward model to distinguish between suitable and unsuitable CV-JD combinations. The pairwise ranking loss function is employed to guide the training of the reward model. This loss function helps the model learn to differentiate between positive and negative pairs effectively, contributing to its ability to accurately assess the compatibility between CVs and JDs.During the inference phase, the trained reward model can receive a CV and a JD pair and provide a matching score indicating the extent to which the CV and JD align. This matching score serves as an indicator of the suitability of the job for the specific job seeker, allowing for the evaluation and assessment of potential job matches.
-
Reinforcement Learning Phase: The third step in the GIRL framework involves aligning the generator model and the reward model using a reinforcement learning approach. This step serves the purpose of fine-tuning the generator’s output to better match the preferences and requirements of recruiters or employers, ensuring that the generated job descriptions are not only suitable for the job seekers but also cater to the practical demands of the job market.Alignment, in this context, refers to the process of adjusting the parameters and behavior of the generator model based on the feedback received from the reward model, which evaluates the quality of the generated job descriptions. By using reinforcement learning techniques such as Proximal Policy Optimization (PPO), the generator can learn to produce job descriptions that not only reflect the characteristics of the job seekers but also align with the expectations and preferences of employers, as captured by the feedback provided to the reward model.
So, in summary, about the connection between these three steps, we can say that:
- In the first step, the job descriptions are generated solely based on the information contained in the CVs of the job seekers. This step ensures that the generated job descriptions are tailored to the specific characteristics and preferences of the job seekers.
- In the second step, the system considers the feedback from the employers, allowing the model to discern whether a particular job seeker’s CV aligns well with the job description, as perceived by the employers. This step introduces a crucial dimension where the compatibility between the CV and the job description is evaluated based on the feedback from the employers, making the recommendation process more comprehensive.
- The third step then takes the learning from the second step and utilizes reinforcement learning techniques to further align the generated job descriptions with the preferences and expectations of the employers. This step ensures that the generator model in the first step is continuously fine-tuned to produce job descriptions that not only match the job seeker’s characteristics but also resonate more closely with the preferences and requirements of the employers.
Experiments
The primary aspects of the experimental setup are outlined below:
- Datasets: The datasets used in this paper comes from one of the largest online recruitment platform in China. In this platform, each job seeker has a CV, encompassing their basic demographic information, educational background, and work experience. Meanwhile, each job is associated with a JD, detailing the responsibilities of the role, the compensation package, and etc.
- Baseline Methods: It seems that the evaluation focused on comparing different components or variations of their proposed GIRL approach against specific models or variants. Instead of completely replacing the entire system, they compared the performance of different elements and configurations within their GIRL approach, such as comparing the performance of GIRL with GIRL-SFT and other LLMs for the generation quality evaluation.
Conclusion
In this paper, the authors introduced the GIRL framework, a novel approach for job recommendation that combines generative models with reinforcement learning techniques. Through our comprehensive evaluation, we demonstrated the effectiveness of the GIRL approach in generating high-quality job descriptions and enhancing the performance of traditional recommendation systems. By leveraging the power of large language models and reinforcement learning, they were able to bridge the gap between job seekers and employers, providing more accurate and personalized job recommendations.
Here are some more articles relevant to this one: