Paper Review - Week 25
Here is the list of the most interesting papers published in this week:
- A Preliminary Study of ChatGPT on News Recommendation: Personalization, Provider Fairness, Fake News
- Towards Open-World Recommendation with Knowledge Augmentation from LLMs
A Preliminary Study of ChatGPT on News Recommendation: Personalization, Provider Fairness, Fake News
Introduction
The paper primarily focuses on evaluating the performance of ChatGPT in the context of news recommendation from various perspectives, including personalized news recommendation, news provider fairness, and fake news detection. Additionally, the study examines the impact of different prompt formats on ChatGPT’s response generation and overall performance. While it does not explicitly target a specific research gap, it contributes to the broader understanding of the capabilities and limitations of large language models like ChatGPT in addressing crucial aspects of news recommendation. So, this review post only consists the Experiment section, where their leveraged strategies is briefly discussed.
Experiments
Their experiments are categorized into different sections based on the targeted tasks.
Personalization
They proposed three prompting approaches to evaluate personalisation:
-
The initial method involved simple textual prompting, where they listed the watched movies and the candidate items, prompting the recommender to choose one from the candidates. However, they noted instances where ChatGPT occasionally recommended an already-watched movie instead of selecting from the candidate list.
-
In the second approach, the candidate movies were embedded into the prompt using the JSON format. In this approach, the watched movies are in a list format. The authors noted that there is still the chance of providing an already-watched movie as the recommendation.
-
The third approach incorporated both the history of watched movies and the candidate movies in JSON format. The results show that in this prompt, the recommendations are always from the candidate list. So, this is the only approach that resulted in getting reasonable recommendations for personalization.

News Provider Fairness
The authors aim to mitigate biases related to news provider fairness by explicitly addressing the concept of fairness in the prompts. They divide the news providers into two groups: popular and unpopular, and they use this division as a basis for constructing the prompts. The prompts include instructions regarding the specific numbers of news articles to be included from both popular and unpopular news providers. Additionally, in some of the prompt styles, they explicit mention of the lists of popular and unpopular providers. This approach helps to evaluate ChatGPT’s ability to provide recommendations that give equal opportunities to news articles from both popular and unpopular providers, thereby addressing any inherent biases in the recommendation process. A sample of these 6 prompt styles are depicted in the following figure:

The authors also introduced another group of prompting styles that explicitly instruct ChatGPT to consider fairness when generating recommendations. These prompts directly emphasize the concept of fairness, urging ChatGPT to ensure that the recommendations provided maintain an equitable balance between popular and unpopular news providers. The three prompting style proposed in this regard are as follows:

Trustfulness News Recommendation
In this task, the authors focus on how to ensure trustful news recommendation and mitigate the risk of recommending fake news. By including the news ID of the trusted or reliable news articles directly into the prompt, the researchers restrict the recommendation process to solely include articles that have been identified as trustworthy. This method effectively limits the scope of recommendations to only those articles that have met specific criteria for trustworthiness, thereby minimizing the potential for ChatGPT to generate or recommend fake news articles.
Towards Open-World Recommendation with Knowledge Augmentation from LLMs
Introduction
With the emergence of large language models (LLMs) providing access to open-world knowledge, there exists a significant opportunity to revolutionize traditional closed recommendation systems. This paper introduces the Knowledge Augmented Recommendation (KAR) framework, designed to leverage the potential of LLMs in enriching recommendation systems. KAR emphasizes the integration of reasoning and factual knowledge extracted from LLMs to facilitate an in-depth understanding of user preferences and item characteristics. Through a three-stage architecture, KAR aims to bridge the gap between closed and open-world systems, enabling more accurate and personalized recommendations for users.
Research Gap
This paper tries to address several gaps in existing research related to LLM-based recommendation systems and traditional recommendation systems. Some of the specific gaps include:
-
Limited Knowledge Extraction: Traditional recommendation systems often rely on a limited set of features and knowledge, which may not fully capture the diverse preferences of users. The paper seeks to address this limitation by leveraging LLMs to extract a wider range of open-world knowledge beyond the original dataset.
- Compositional Gap: The compositional gap refers to the limitations of LLMs in accurately generating the correct answer for complex and compositional questions. It implies that while LLMs might excel at answering simpler sub-questions, they may fail to correctly answer more complex queries that involve multiple reasoning steps. This gap arises due to the intricate and multifaceted nature of user preferences, which cannot always be accurately captured or represented by the LLMs in a single step.
- Performance Limitations due to Information Misalignment: The paper acknowledges that there can be a mismatch between the knowledge generated by LLMs and the inferred user preferences in recommendation systems. This misalignment can limit the overall performance of recommendation systems. The proposed framework aims to align the reasoning knowledge and the item factual knowledge to ensure that they are effectively utilized in recommendation processes.
- Computational- and Resource-intensive Inference: Given the large size and computational demands of LLMs, the inference process can be time-consuming and resource-intensive, making it challenging to meet the real-time latency requirements of large-scale recommendation systems. The paper introduces a speed-up approach that involves pre-storing the knowledge representation generated by the LLMs, thereby significantly reducing the inference overhead and enhancing the efficiency of the recommendation process.
Solution: KAR
The proposed solution is a recommendation system that leverages LLMs to access open-world knowledge, thus avoiding getting stuck within closed systems. The framework consists of three components, each serving a unique purpose:
-
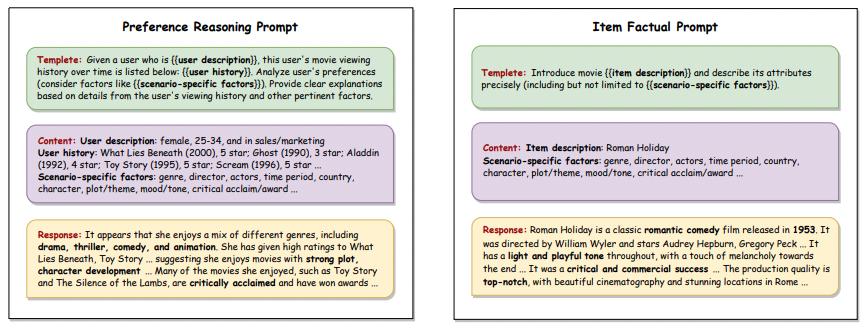
Knowledge Reasoning and Generation Stage: This phase primarily focuses on the extraction of comprehensive information about items and users through the utilization of LLMs. Let’s consider the scenario of movie recommendation as an example. By extracting detailed information about movies and establishing a more precise understanding of user preferences, we can significantly enhance the recommendation process. Specifically, the knowledge extracted about user preferences is referred to as Reasoning Knowledge, whereas the information extracted about the items is termed Factual Knowledge. To extract the reasoning and factual knowledge, a pioneering technique known as factorization prompting is introduced. This technique will be thoroughly explained in the subsequent sections.
-
Knowledge Adaptation Stage: Once the knowledge about items (reasoning knowledge) and users (factual knowledge) is extracted from LLMs, it must be properly formatted and adapted for integration into the recommendation systems. To facilitate this process, a cutting-edge hybrid-expert approach has been proposed, which will be comprehensively elaborated upon later.
-
Knowledge Utilization: The main point of this component is to effectively utilize the knowledge augmented vectors in the recommendation system to generate optimal outputs. These knowledge augmented vectors, derived from the reasoning augmented vector and the factual augmented vector, are seamlessly integrated into the recommendation model. They are treated as supplementary fields in the feature interaction layer of the recommendation model, allowing for explicit interaction with other categorical features. By incorporating these augmented vectors into the recommendation model, the system combines both open-world knowledge and recommendation-specific knowledge. This fusion enables the system to provide users with highly informed and deeply personalized recommendations.
An overview of the whole KAR system is depicted in the following figure:
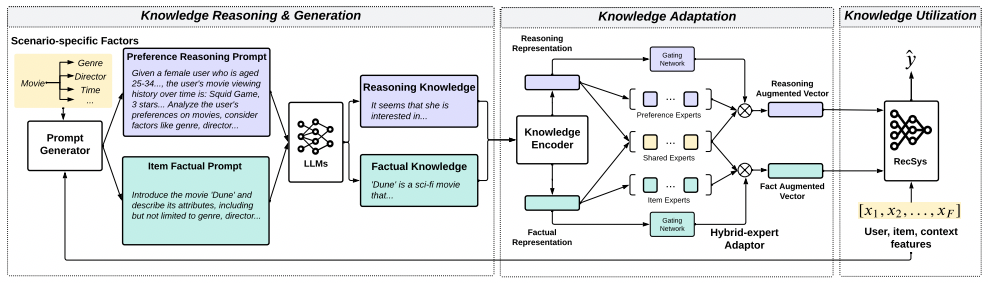
Factorization Prompting
The factorization prompting approach is a key technique employed in the Knowledge Reasoning and Generation Stage. It is specifically designed to address the challenge of extracting precise and comprehensive knowledge from LLMs about user preferences and item characteristics.
The factorization prompting approach is rooted in the concept of decomposing complex reasoning tasks into more manageable subproblems by identifying the major factors that contribute to user preferences and item attributes. By breaking down the decision-making processes into these essential factors, the LLMs can more effectively capture and generate nuanced Reasoning Knowledge and Factual Knowledge.
For instance, in the context of movie recommendation, these factors might encompass various critical dimensions, including genre, actors, directors, theme, mood, and production quality. By explicitly incorporating these factors into the prompting mechanism, the LLMs can more accurately identify the key elements that influence user preferences.
This factorization prompting strategy alleviates the compositional gap often observed in LLMs, allowing the system to better capture the diverse and multifaceted nature of user interests and preferences. Consequently, the generated Reasoning Knowledge and Factual Knowledge become more aligned and tailored to the specific requirements of the recommendation process, leading to more effective and personalized recommendations.
To better illustrate the factorization prompting approach, let us have a look at the following figure. Also, it is worth mentioning that, in this figure, the term Scenario-specific Factors is used. Different scenarios might correspond to various domains such as movie recommendation, news recommendation, or product recommendation. Each of these domains involves distinct sets of considerations that influence user preferences and item characteristics. For instance, in movie recommendation, scenario-specific factors could include genre, actors, directors, theme, mood, and production quality, as these aspects significantly impact a user’s likelihood of being interested in a particular movie.
Hybrid-Expert Adapter
The hybrid-expert adaptor in the proposed framework is based on Multi-Layer Perceptrons (MLPs) and is a crucial component in the Knowledge Adaptation stage of the system. It receives the reasoning knowledge and factual knowledge that have been extracted from the Knowledge Reasoning and Generation step. The adapters function to create refined representations of this knowledge, enhancing its compatibility with the recommendation system.
There are three types of adapters (MLPs) utilized in this process. Firstly, there are the preference experts that exclusively utilize the reasoning knowledge. Secondly, the shared experts leverage both the reasoning knowledge and factual knowledge. Lastly, the item experts focus solely on the factual knowledge. By considering these different types of experts, the system can incorporate diverse forms of knowledge to enrich the final representations.
To control the impact of each expert representation, learnable weights called gating networks are employed. These gating networks are instrumental in regulating the influence of the different expert types, ensuring a balanced and comprehensive integration of knowledge.
Through a series of matrix multiplications and additions, the hybrid-expert adaptor generates two vectors: the reasoning augmented vector representing the user and the fact augmented vector representing the item. These vectors are then fed into the recommendation system to predict whether the item should be recommended to the user (i.e., point-wise recommendation). This comprehensive process allows the system to leverage a combination of specialized knowledge and provide more accurate and personalized recommendations.
All of these adapters and learnable parameters are trained concurrently with the training of the recommendation system.
Experiments
The experiments conducted in the paper aimed to evaluate the performance of the proposed recommendation system, KAR, in sequential recommendation. The primary aspects of the experimental setup are outlined below:
- Datasets: The experiments were conducted on the MovieLens-1M dataset, which contains 1 million ratings from 6000 users for 4000 movies.
- Baseline Methods: The experiment compared the proposed KAR framework with several baseline methods, including P5, UniSRec, and VQ-Rec.
- Evaluation Metrics: The evaluation metrics used in the experiments were AUC and Binary Cross-Entropy Loss.
- Results: The results demonstrated that the KAR framework significantly improved the performance of the backbone models across various types of baseline models. It outperformed models based on text pretraining or user sequence pretraining, achieving a notable improvement in AUC and BCE. The experiments revealed the effectiveness of incorporating open-world knowledge from large language models (LLMs) into recommendation systems.
Conclusion
In conclusion, the exploration and evaluation of the Knowledge Augmented Recommendation (KAR) framework underscore its significant contributions to the modern recommendation systems. By effectively harnessing the power of LLMs and integrating reasoning and factual knowledge, KAR has demonstrated substantial improvements in recommendation performance over diverse backbone models and baseline methods.
Here are some more articles relevant to this one: