Paper Review - Week 43
Here is the list of the most interesting papers published in this week:
Query Rewriting for Retrieval-Augmented Large Language Models
Introduction
The attempt for improving question-answering systems has led to innovative approaches, and this study introduces a novel paradigm by incorporating a trainable query rewriter within an open-domain question-answering framework. Departing from traditional retrieve-then-read methods, the inclusion of a rewriting step before querying the retriever module seeks to enhance the relevance and informativeness of retrieved documents. This research aims to address the crucial role of query formulation in influencing the overall performance of question-answering systems, particularly in scenarios involving complex, multi-hop reasoning and multiple-choice questions.
Research Gap
The authors argue that the original retrieval query is often fixed and may not align optimally with the actual knowledge needed. Existing retrieval-augmented language models have largely overlooked the adaptation of the query itself, which serves as the input for the retrieve-then-read pipeline. Therefore, introducing a query rewriting step is proposed to clarify and adapt the retrieval need from the input text.
Solution: Rewrite-Retrieve-Read
The paper proposes a new framework called Rewrite-Retrieve-Read, which modifies the traditional retrieve-then-read pipeline used in retrieval-augmented language models.
In the standard retrieve-then-read pipeline, the original query is passed directly to the retriever, which retrieves relevant documents. The language model then reads these documents and generates an answer. However, the paper introduces a crucial modification by adding a “Rewrite” step before the retrieval. In this step, the original query is rewritten by a trainable rewriter model before being passed to the retriever.
The motivation behind this additional step is to bridge the gap between the input text and the knowledge needed for retrieval. By allowing the language model to generate the query and then refining it through rewriting, the system aims to clarify and improve the retrieval need from the input text. This rewriting step is trainable and is fine-tuned using reinforcement learning based on feedback from the language model reader.
The objective is to adapt the query to better suit the capabilities and limitations of the frozen retriever and language model reader. This approach is designed to enhance the retrieval process, potentially leading to the selection of more relevant documents and, consequently, improving the overall performance of the retrieval-augmented language model on downstream tasks such as open-domain QA and multiple-choice QA.
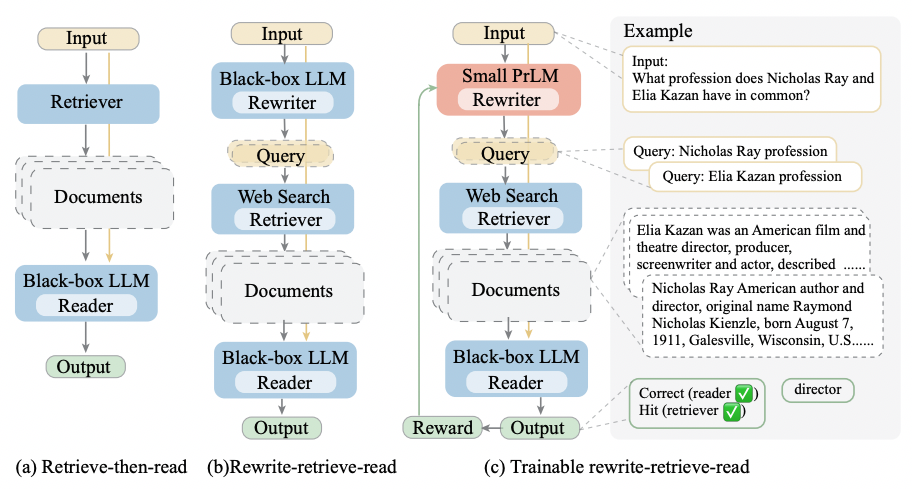
Rewriter Module
In this approach, the rewriter module is trained to generate better queries for downstream tasks. The training dataset is created by asking an LLM to rewrite each input query multiple times, and then selecting the best-performing rewrite. This dataset pairs original queries with their most performant rewritten versions. The rewriter, based on the T5 model, goes through two phases: an initial warm-up using standard log-likelihood training and then fine-tuning with reinforcement learning (RL). In RL, the rewriter learns to generate queries that lead to improved task performance. The training process involves maximizing expected rewards, utilizing Proximal Policy Optimization, and using metrics like exact match and F1 score for evaluation. The goal is to adapt the rewriter to produce task-specific queries that enhance the overall performance of the retrieval-augmented language model.
Experiments
The experiments are conducted on two main tasks:
- Open-domain QA:
- Datasets: HotPotQA, AmbigNQ, PopQA
- Models: ChatGPT for reader and frozen rewriter
- Metrics: EM, F1, Hit
- Multiple-choice QA: Dataset: Massive Multi-task Language Understanding (MMLU)
- Categories: Humanities, STEM, Social Sciences
- Models: ChatGPT as a frozen rewriter and reader
- Metric: EM; questions with options are rewritten into search queries
Conclusion
In conclusion, the integration of a trainable query rewriter proves to be a promising avenue for advancing open-domain question-answering systems. The experiments demonstrate the consistent performance gains achieved through query rewriting. Their evaluations across different tasks reveals the adaptive nature of the trainable rewriter, outperforming standard retrieval methods in specific contexts.
Here are some more articles relevant to this one: