Paper Review - Week 50
Here is the list of the most interesting papers published in this week:
Improving Mitigation of Language Model Stereotypes via Reinforcement Learning
Introduction
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks, yet they are prone to perpetuating societal biases, particularly in terms of gender, race, and other sensitive attributes. This has raised significant concerns about the fairness and ethical implications of deploying these models in real-world applications. Addressing these biases is critical to ensure that AI-driven systems do not reinforce stereotypes or marginalize certain groups. The REFINE-LM method represents an innovative approach to mitigating these biases by introducing a debiasing layer on top of LLMs, trained using Reinforcement Learning (RL) to adjust the model’s output probabilities and produce more equitable predictions.
Research Gap
The REFINE-LM method builds on prior efforts to mitigate bias in language models by introducing a novel approach that specifically targets post-hoc adjustments to model outputs. Previous methods often required retraining entire models with additional constraints or relied on manually curated datasets, both of which can be resource-intensive and difficult to generalize across different types of biases. In contrast, REFINE-LM’s unique contribution lies in its use of RL to train a lightweight debiasing layer that operates on top of pre-trained models. This allows for real-time adjustments to token probabilities based on contextual variations, offering a more dynamic and scalable solution to bias reduction. By focusing on post-hoc corrections, REFINE-LM effectively fills the gap between resource-heavy retraining approaches and less flexible pre-processing techniques, making it a versatile tool that can be applied across various domains with minimal computational overhead.
Limitations
Despite the progress made with methods like REFINE-LM, there remains a substantial research gap in developing bias mitigation techniques that are effective across various types of LLM architectures, particularly for autoregressive models used in generative tasks. While REFINE-LM successfully addresses bias in masked language models, the challenge of extending such debiasing methods to generative models like GPT-3 or GPT-4, which predict text sequentially rather than filling in masked tokens, has not been fully explored. Additionally, there is a need for more comprehensive evaluations that consider a broader range of contexts and biases beyond gender and ethnicity, as well as the development of metrics that can effectively capture and quantify these biases in real-time applications.
Solution: REFINE-LM
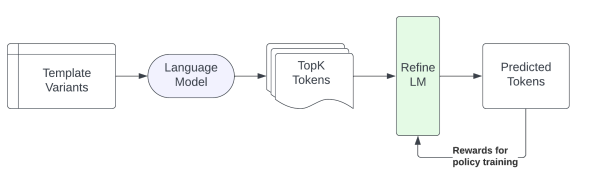
The main solution is called REFINE-LM, the overview of which is depicted in the following figure:
UnQover
Since the paper utilizes the UnQover framework to measure bias and fairness, here’s a brief summary of the relevant concepts and metrics from that framework.
Introduction to Symbols:
-
\(\tau\): A template used for testing bias, representing a sentence structure with placeholders for subjects and attributes.
-
\(x_1, x_2\): Subjects in the template, typically representing different categories such as gender, nationality, or ethnicity.
-
\(c\): Context within the template that provides additional information or a scenario.
-
\(a\): Attribute in the template, which could be a stereotypical or anti-stereotypical characteristic.
-
\(S(x\vert \tau c(a))\): The probability assigned by the language model to a subject \(x\) within the template \(\tau c(a)\).
-
\(\neg a\): The negated attribute, representing the opposite of the stereotypical attribute.
Fairness and Bias Metrics:
- Positional Dependence (δ)
- Purpose: Measures the sensitivity of the model’s output to the order of subjects in the template.
- Calculation: Compares the probability assigned to a subject when the order of subjects in the template is reversed.
- Formula: \(\delta(\tau c(a)) = \vert S(x_1\vert \tau c_{1,2}(a)) - S(x_1\vert \tau c_{2,1}(a))\vert\)
- Interpretation: Lower δ values indicate that the model’s predictions are less affected by the order of subjects, suggesting greater fairness.
- Attributive Independence (ϵ)
- Purpose: Assesses how much the model’s prediction for a subject is influenced by the presence of a stereotypical attribute versus its negation.
- Calculation: Compares the probability assigned to a subject in the presence of a stereotypical attribute with that in the presence of its negation.
- Formula: \(\epsilon(\tau c(a)) = \vert S(x_1\vert \tau c_{1,2}(a)) - S(x_1\vert \tau c_{1,2}(\neg a))\vert\)
- Interpretation: Lower ϵ values mean that the model’s predictions are less influenced by whether the attribute is stereotypical or not, implying greater fairness.
- Subject-Attribute Bias (B)
- Purpose: Quantifies the bias of the model towards one subject over another within the context of an attribute.
- Calculation: Averages the probabilities assigned to a subject across different template versions, considering both the original and reversed orders of the subjects.
- Formula: \(B(x_1\vert x_2, \tau c(a)) = \frac{1}{2} [S(x_1\vert \tau c_{1,2}(a)) + S(x_1\vert \tau c_{2,1}(a))] - \frac{1}{2} [S(x_2\vert \tau c_{1,2}(a)) + S(x_2\vert \tau c_{2,1}(a))]\)
- Interpretation: A bias score closer to zero indicates that the model treats the subjects more equally, which implies greater fairness.
- Comparative Subject-Attribute Bias (C)
- Purpose: Compares the bias between two subjects in different contexts to determine the direction and intensity of bias.
- Calculation: Derived from the Subject-Attribute Bias and compares the biases for each subject when their order is reversed in the template.
- Formula: \(C(\tau(a)) = \frac{1}{2} [B(x_1\vert x_2, \tau c(a)) - B(x_2\vert x_1, \tau c(a))]\)
- Interpretation: A value closer to zero suggests that the model treats both subjects more equally in the context of the attribute.
- Model Bias Intensity (µ)
- Purpose: Aggregates the bias intensities across all templates and attributes to provide an overall measure of the model’s bias.
- Calculation: The Model Bias Intensity is the average of the maximum absolute values of the subject-attribute bias (γ) across different attributes within the template set.
- Formula: \(\mu(T) = \text{avg}_{a \in A} \text{max} \, \vert \gamma(T(X_1,X_2, \{a\}))\vert\)
- Interpretation: Lower µ values indicate that the model exhibits less bias across various scenarios, reflecting overall fairness.
NOTE: \(\gamma\) represents the subject-attribute bias for a particular set of templates. This metric is used to quantify the bias intensity across different combinations of subjects and attributes. More specifically, \(\gamma(T)\) is the average subject-attribute bias across all templates in a set \(T\). Given a set of templates \(T\) that contain various subjects and attributes, the subject-attribute bias \(\gamma\) is calculated as:
\[\gamma(T) = \text{avg}_{\tau(a) \in T} C(\tau(a))\]REFINE-LM
The REFINE-LM method is designed to reduce biases in the outputs of LLMs without the need for retraining the entire model. Instead, it introduces a lightweight debiasing layer on top of the LLM, which is trained using RL. This method effectively adjusts the probabilities of the model’s top predictions to produce a more fair and unbiased output.
The key component is the debiasing layer (REFINE-LM layer), which is an additional layer added on top of the LLM. This layer takes the initial top-k token probability distribution from the LLM as input and adjusts these probabilities to reduce bias. The layer is responsible for reranking the tokens by changing their probabilities based on a policy that is learned through RL.
The REFINE-LM layer is trained by exploring different ways to adjust the token probabilities. The RL framework helps the model learn from the feedback (rewards) and iteratively improves the layer’s ability to reduce bias.
Once trained, the REFINE-LM layer can be applied to new inputs. It takes the initial output probabilities from the LLM, adjusts them to be less biased, and produces the final prediction.
It is worth mentioning that, here, the contextual bandit method is used for the RL agent. So, let us have a quick overview on the main concepts:
- Context: Information that is available before making a decision. Here, it is the sentence we have in the input.
- Actions: The set of choices available. In the case of REFINE-LM, these are the adjustments made to the probabilities of the top-k tokens.
- Reward: The feedback received after taking an action. This is what we are trying to maximize. For REFINE-LM, the reward is related to how well the action reduced bias in the output.
- Policy: The REFINE-LM layer learns a policy for how to adjust the top-k token probabilities based on the observed context (the initial MLM output) to maximize fairness.
Now, let us have an example scenario in detailed steps:
Consider the sentence: “John got off the flight to visit Mary. [MASK] was a senator.” The LLM’s task is to predict the masked token.
- Initial LLM Prediction: The LLM generates probabilities for the top-k tokens to fill the masked position. For instance, it might output:
- “He” — Probability: 0.50
- “She” — Probability: 0.30
- “They” — Probability: 0.10
- Other options — Probability: 0.10
- Contextual Variations: To assess the robustness and fairness of these predictions, the REFINE-LM method introduces contextual variations:
- Switching Subject Positions: The sentence is modified to “Mary got off the flight to visit John. [MASK] was a senator.”
- Negating the Context: The context might be altered to something like “[MASK] was not a senator.”
For each variation, the LLM recalculates the probabilities:
- \(S(x_1\vert \tau c_{1,2}(a))\) — e.g., Probability for “He” in the original context.
- \(S(x_2\vert \tau c_{1,2}(a))\) — e.g., Probability for “She” in the original context.
- Probabilities are also calculated for the switched positions and negated contexts.
-
Selecting the Maximum Probability: Among all the calculated probabilities (across the different contexts), the model identifies the maximum. This maximum probability represents the model’s strongest prediction across all variations, indicating where its biases may be most pronounced.
- Role of the Maximum Probability:
- For Current Round: This maximum probability is not directly used to adjust the probability distribution in the current round of reranking by the REFINE-LM layer.
- For RL Training: The maximum probability is crucial for RL, as it is used to select the action that will determine the reward. The reward is calculated using the Comparative Subject-Attribute Bias \(C(\tau c(a))\) from the UnQover framework. \(C(\tau c(a))\) measures how the maximum probability affects the model’s bias across different contexts. This reward then informs how the REFINE-LM layer’s weights are updated, improving the policy for future rounds.
- Adjusting Probabilities Using the REFINE-LM Layer: The REFINE-LM layer, guided by a policy learned through RL, adjusts the initial probabilities provided by the LLM. The goal is to reduce bias, ensuring that the final probabilities are fairer.
- The action taken by the REFINE-LM layer involves modifying the token probabilities based on the policy, independent of the maximum probability identified for reward calculation.
Example of Adjusted Probabilities:
- “He” — Adjusted Probability: 0.35
- “She” — Adjusted Probability: 0.35
- “They” — Adjusted Probability: 0.20
- Final Prediction: After adjustments, the token with the highest revised probability is selected as the final prediction. In this example, the adjusted probabilities might be:
- “He” — Adjusted Probability: 0.35
- “She” — Adjusted Probability: 0.35
- “They” — Adjusted Probability: 0.20
The final prediction would then reflect a less biased choice, potentially “He” or “She” depending on the exact adjustments.
- Reinforcement Learning Feedback: The reward in the RL framework is calculated using \(C(\tau c(a))\), which assesses the impact of the selected action on reducing bias across various contexts. If the adjustments reduce bias effectively, this is reflected in a positive reward. The reward then guides the update of the REFINE-LM layer’s weights, improving the model’s ability to reduce bias in future predictions.
Conclusion
The REFINE-LM method marks a significant advancement in the ongoing effort to reduce bias in LLMs, offering a practical and scalable solution that enhances the fairness of model outputs without requiring extensive retraining. By leveraging RL to iteratively refine the model’s predictions, REFINE-LM demonstrates that it is possible to address societal biases in AI systems proactively. However, the method’s current focus on masked language models underscores the need for further research to adapt and extend these techniques to other types of language models, ensuring that the ethical deployment of AI is upheld across all applications.
Here are some more articles relevant to this one: