Paper Review - Week 22
Here is the list of the most interesting papers published in this week:
Reflexion: Language Agents with Verbal Reinforcement Learning
Introduction
The Reflexion framework presents a novel approach to enhancing the performance of Large Language Models (LLMs) by addressing the limitations of traditional Reinforcement Learning (RL) methods. Traditional RL typically involves computationally intensive weight updates and relies on scalar rewards that often lack the nuance needed for effective learning. Reflexion diverges from this paradigm by reinforcing LLMs through verbal feedback instead of weight updates. This feedback, stored in an episodic memory buffer, consists of reflective summaries that provide detailed insights and suggestions for improvement. By leveraging the LLM’s natural language understanding capabilities, Reflexion enables the model to learn iteratively from past experiences, thus enhancing its decision-making, reasoning, and coding capabilities without the need for extensive computational resources.
Research Gap
The Reflexion framework addresses the limitations of traditional RL methods, which involve computationally intensive weight updates and often lack nuanced feedback. Traditional RL typically relies on scalar rewards and extensive model fine-tuning, which can be inefficient and time-consuming. Reflexion introduces a novel approach by reinforcing LLMs through verbal feedback rather than weight updates. This feedback, stored in an episodic memory buffer, consists of reflective summaries that provide detailed insights and suggestions for improvement. This method leverages the LLM’s natural language understanding capabilities, enabling it to learn from past experiences without the need for expensive computational resources.
Compared to existing methods, Reflexion stands out by incorporating memory-based learning and flexible feedback mechanisms, allowing it to be applied across diverse tasks such as sequential decision-making, coding, and language reasoning. Reflexion achieves state-of-the-art performance on several benchmarks, demonstrating significant improvements over baseline agents. By mimicking human reflective learning processes and leveraging the LLM’s capabilities, Reflexion represents a significant advancement in LLM training and reinforcement learning.
Solution: Reflexion
While Reflexion diverges from traditional RL in how it updates the agent (LLM), it still employs RL concepts but in a unique way. Here’s how RL concepts map onto the Reflexion framework:
- Agent: In traditional RL, the agent is typically a neural network that learns a policy by adjusting its weights based on rewards. In Reflexion, the agent is a LLM that generates actions (text) based on a fixed policy.
- Environment: In traditional RL, the environment provides states, receives actions from the agent, and returns rewards and new states. In Reflexion, the environment interacts with the LLM, providing feedback (rewards) based on the LLM’s actions.
- Policy: In traditional RL, the policy determines the agent’s actions and is updated based on rewards to improve performance. In Reflexion, the policy is implicitly defined by the LLM’s capabilities and its use of contextual information from memory.
- Reward: In traditional RL, rewards are used to update the agent’s policy through mechanisms like gradient descent. In Reflexion, rewards are used to generate verbal feedback, which is stored in memory and used to guide future actions.
- Learning Process: In traditional RL, learning involves updating the weights of the agent’s neural network. In Reflexion, learning involves updating the agent’s memory with reflective summaries, which influences future decisions.
- Exploration vs. Exploitation: In traditional RL, agents explore the environment to find better policies and exploit known good actions. In Reflexion, the LLM explores different actions based on feedback stored in memory and exploits successful patterns discovered through reflection.
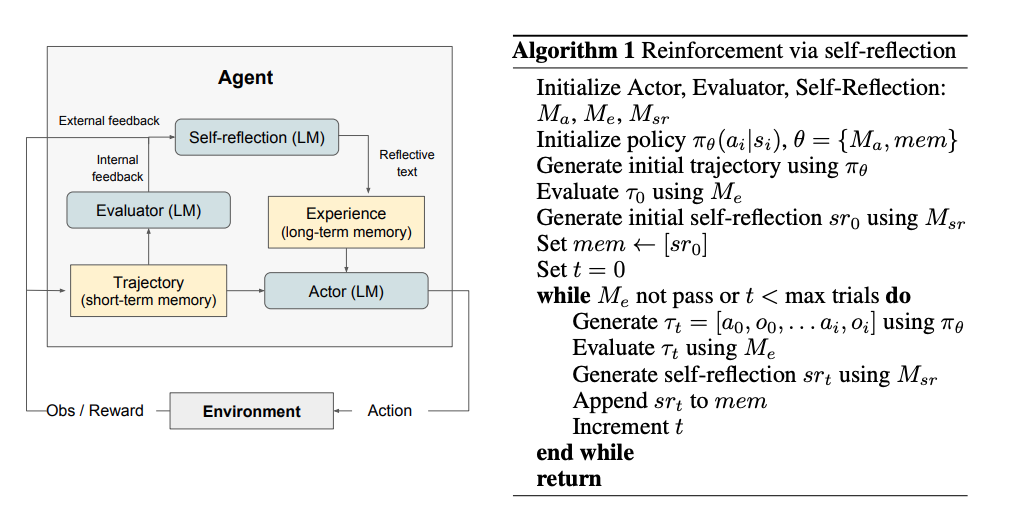
In Reflexion, the LLM (Actor) generates text or actions based on the current state and context from memory, aligning with the policy in RL. The Evaluator \(M_e\) evaluates the output of the Actor and provides a reward score, corresponding to the reward function in RL. The Self-Reflection model (\(M_{sr}\)) generates reflective feedback based on the reward and trajectory, which is stored in memory. This acts as an indirect way of updating the policy by changing the context the LLM uses to make decisions.
Reflexion Process:
- Generation of Initial Trajectory: The LLM (Actor) interacts with the environment to generate an initial trajectory \(\tau\).
- Evaluation: The Evaluator assesses the trajectory and produces a reward \(r\).
- Self-Reflection: The Self-Reflection model uses the trajectory \(\tau\) and reward \(r\) to generate a verbal summary \(sr\). This summary captures the agent’s reflections on its performance, highlighting what went wrong and suggesting improvements.
- Updating Memory: The reflective summary \(sr\) is stored in the agent’s memory. In subsequent trials, this memory provides context and guidance to the LLM, helping it to avoid past mistakes and make better decisions.
- Iterative Improvement: The process of generating trajectories, evaluating them, creating self-reflections, and updating memory continues iteratively. The agent leverages the accumulated memory to improve its performance over time.
The whole process along with the psudo-code of the alogrithm is as follows:
Advantages:
- Lightweight: The approach doesn’t require computationally expensive weight updates and fine-tuning.
- Nuanced Feedback: Verbal feedback can be more detailed and specific compared to scalar rewards.
- Explicit Memory: The agent has an interpretable memory of past experiences that can guide future actions.
- Scalability: As LLM capabilities improve, this method can become even more effective.
In a programming task, the LLM might generate a piece of code. The Evaluator checks the code against test cases and provides a reward based on correctness. Instead of updating the LLM’s weights, the Self-Reflection model generates feedback like, “The function failed because it didn’t handle edge cases correctly. Consider adding checks for empty input.” This feedback is stored in memory and used in the next coding attempt.
The Reflexion framework cleverly leverages the existing capabilities of LLMs and augments them with a memory system driven by verbal feedback, enabling continuous improvement without the need for traditional weight updates in RL.
Experiments
The primary aspects of the experimental setups are as follows:
Sequential Decision-Making (ALFWorld)
Task: The task involves solving multi-step problems in text-based environments, such as finding and manipulating objects.
Dataset: ALFWorld, a suite of text-based environments derived from TextWorld, encompassing 134 different tasks related to finding, moving, and manipulating objects.
Baselines:
- ReAct: An action generation model that uses intermediate thoughts to solve tasks.
Evaluation Metrics:
- Success Rate: The proportion of tasks completed successfully.
- Error Classification: Identifying types of errors such as hallucinations or inefficient planning.
Results:
- Performance: Reflexion agents significantly outperformed the ReAct baseline, completing 130 out of 134 tasks.
- Error Reduction: The use of reflective feedback reduced error rates due to hallucinations and inefficient planning.
Reasoning (HotpotQA)
Task: The task tests the model’s ability to answer complex questions by reasoning over multiple supporting documents.
Dataset: HotpotQA, a large dataset with 113k question-answer pairs requiring reasoning over multiple Wikipedia articles.
Baselines:
- Chain-of-Thought (CoT): A prompting method generating intermediate reasoning steps to arrive at a final answer.
- ReAct + CoT: Combines reasoning and action generation for more complex tasks.
Evaluation Metrics:
- Exact Match (EM): The percentage of answers that match the ground truth exactly.
- Improvement over Trials: Measuring how the success rate changes over multiple trials.
Results:
- Performance: Reflexion improved performance by 20% on HotpotQA reasoning tasks compared to baseline approaches.
- Iterative Improvement: Reflexion agents demonstrated the ability to iteratively improve accuracy through self-reflection.
Programming
Task: The task involves writing correct code based on problem descriptions, including generating and debugging code in Python and Rust.
Datasets:
- HumanEval: A benchmark for evaluating the correctness of function implementations based on given problem descriptions.
- MBPP (ManyBabies Programming Problems): A set of programming challenges in Python.
- LeetcodeHardGym: A newly introduced dataset consisting of 40 hard-rated Leetcode questions in 19 programming languages.
Baselines:
- AlphaCode: A code generation model evaluating generations on hidden test cases.
- CodeT: Uses self-generated unit tests to score function implementations.
- Self-Debugging: Employs debugging components to improve existing implementations.
- CodeRL: A reinforcement learning framework for code generation and debugging.
Evaluation Metrics:
- Pass@1: The accuracy of the first code generation sample passing all test cases.
- False Positive Rate: The proportion of incorrect solutions that pass self-generated unit tests.
- Accuracy: The overall correctness of the code implementations.
Results:
- HumanEval: Reflexion achieved a Pass@1 accuracy of 91% in Python, surpassing the previous state-of-the-art GPT-4 at 80%.
- MBPP: Reflexion maintained high performance in Python and Rust, demonstrating its language-agnostic capabilities.
- LeetcodeHardGym: Reflexion outperformed GPT-4 by achieving a higher pass rate on challenging Leetcode problems.
In summary, the Reflexion framework demonstrated significant improvements across various tasks by leveraging reflective feedback stored in memory, highlighting its effectiveness and potential for further enhancement as LLM capabilities evolve.
An example scenario for three of the main tasks is as follows:

Conclusion
The Reflexion framework significantly advances the field of LLM training by introducing memory-based learning and verbal reinforcement, which allows models to improve iteratively without the need for computationally expensive fine-tuning. Through the use of reflective feedback stored in memory, Reflexion achieves state-of-the-art performance across various tasks, including sequential decision-making, coding, and language reasoning. It surpasses existing methods, such as GPT-4, by demonstrating substantial improvements in benchmarks like the HumanEval coding test. By mimicking human reflective learning processes and leveraging the inherent strengths of LLMs, Reflexion provides a flexible and efficient alternative to traditional RL methods, representing a significant leap forward in the development of intelligent language agents.
Here are some more articles relevant to this one: