Paper Review - Week 19
Here is the list of the most interesting papers published in this week:
Recommendation as Instruction Following: A Large Language Model Empowered Recommendation Approach
In this paper, the authors are focusing on using instruction following, one of the most interesting capabilities of Large Language Models (LLM), to improve the existing recommendation systems. The main reason behind that is that by using the instruction-following capability, it would be possible to create a recmmendation system with generalization ability to be able to handle the unseen data.
To create such instructions, they take three aspects into account:
- User Preference (P), which is the inherent and long-term user preferences. User preferences can be divided into three different levels:
- None (P0)
- Implicit Preference (P1)
- Explicit Preference (P2)
- Intention (I), which is the immediate demands of the user for certain types of items. The user intention can be different from user long-term preferences. User intentions can be divided into three different levels:
- None (I0)
- Vague Intention (I1)
- Specific Intention (I2)
- Task Form (T), which indicates how to formulate the instructions for apecific tasks. The task forms can be one of the following items:
- Pointwise Recommendation (T0)
- Pairwise Recommendation (T1)
- Matching (T2)
- Reranking (T3)
All of the mentioned aspects for instruction creation are summarized in the following figure:
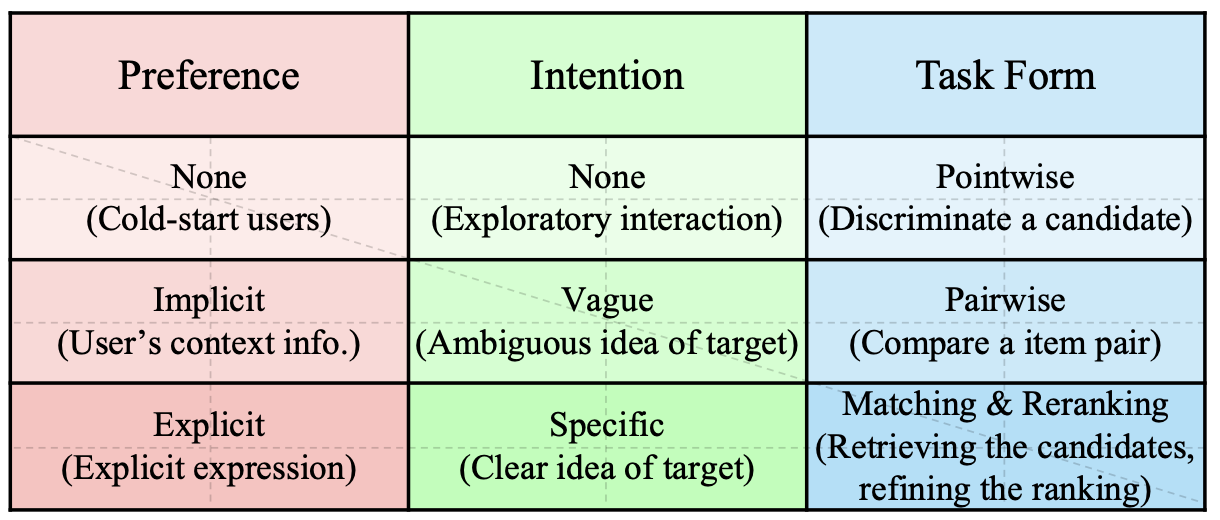
By having different combinations of the three aspects, about 36 (3 \(\times\) 3 \(\times\) 4) instruction templates are created. Moreover, several techniques are employed to increase the diversity of instruction templates which are explained later. The following figure representes serveral instruction examples, to make it clear that how instruction templates are instantiated (color coding: red=preference, green=intentions, blue=task):

Now, the question is how to fill each aspect placeholder in the instruction example? In other words, how user preferences (red color), user intentions (green color), and task forms (blue color) should be filled? The main strategy for doing so is to automatically generate the prompt by leveraging a strong teacher-LLM (e.g., GPT-3) to be able to generate personaliezd prompt for each user. So, in what follows, we provide more details about how the three aspects–i.e., preference, intention, and task form–can be extracted and annotated to be injected into the instruction templates.
- Preference Annotation: Different strategies are used for annotating different preference levels:
- Implicit Preference (P1): The item titles are used as representations to create users’ historical interactions. After creating the historical interation, the following instruction template is filled:
The user has previously purchased the following items: {USER_INTERACTION_HISTORY}. - Explicit Preference (P2): In this case, since most of the datasets do not contain users’ explicit preferences, the teacher-LLM is asked to generate explicit expressions of user preferences based on the historical interactions. For example, the following image represents how the teacher-LLM is asked to generate users’ explicit preferences:
- Implicit Preference (P1): The item titles are used as representations to create users’ historical interactions. After creating the historical interation, the following instruction template is filled:
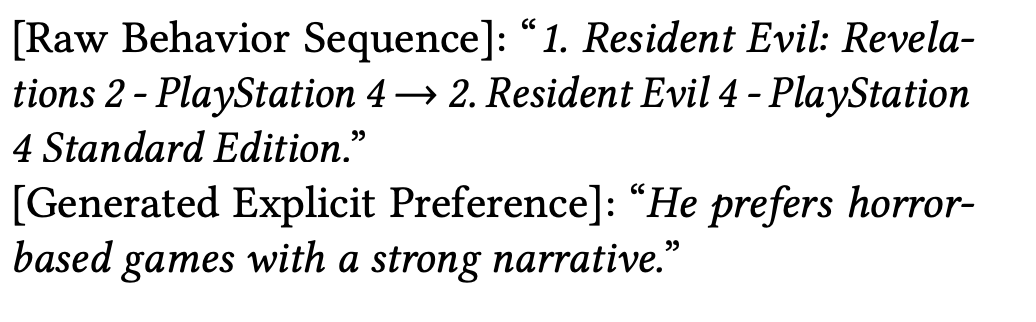
- Intention Annotation: Similar to the preference annotation process, the intention annotaton strategy is determined based on the intention levels:
- Vague Intention (I1): To extract the vague intentions, reviews are considered to be very useful and informative, since they provide valuable evidence about user’s personal tastes. So, here, the teacher-LLM is provided by item review (I am not sure if the review of the user is used or all the review for a specific item from other users) and is asked to generate the user’s intention. An example is provided in the following figure:
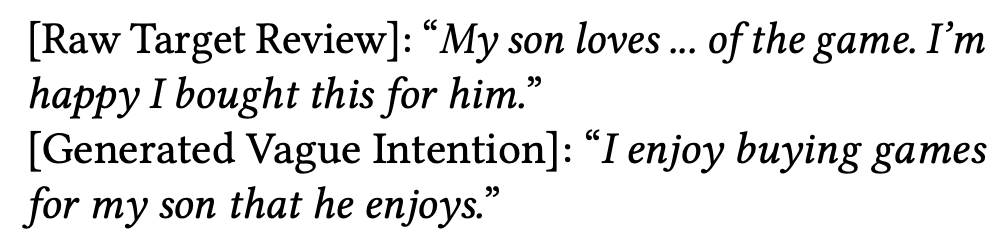
- Specific Intention (I2): In this case, the category of items with which user had intertions are considered as their specific intentions. For example, it can be:
Video Games, PC, Accessories, Gaming Mice.
- Task Form Annotation: The task form annotation is determined by the task type:
- Pointwise Recommendation (T0):
Based on the {USER_RELATED_INFORMATION}, is it likely that the user will interact with {TARGET_ITEM} next?The model is supposed to answer yes or no! - Pairwise Recommendation (T1): It is not implemented yet.
- Matching (T2):
Predict the next possible item. - Reranking (T3):
Select one item from the following {CANDIDATES}.
- Pointwise Recommendation (T0):
Moreover, several techniques are employed to increase the diversity of instruction templates, including:
- Turn the Task Around: It is based on swaping between the input and output of normal instructions. An example of using this strategy is represented in the following figure:

- Enforcing the Relatedness between Preference and Intention: This strategy is based on the hypothesis that the revealed short-term user intentions and their long-term prefernces are highly related. An example of this strategy is as follows:

For evaluation, they have used two datasets: Games and CDs from Amazon. Also, as baselines, they have considered BERT4Rec, SASRec, GPT3.5, TEM, and DSSM. The metrics used for evaluation are Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDGC). According to their results, InstructRec could outperform the baselines in many cases.
Here are some more articles relevant to this one: