Paper Review - Week 21
Here is the list of the most interesting papers published in this week:
- Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models
- Leveraging Large Language Models in Conversational Recommender Systems
- Self-Refine: Iterative Refinement with Self-Feedback
- SelfInstruct: Aligning Language Models with Self-Generated Instructions
Self-Refine: Iterative Refinement with Self-Feedback
Introduction
The paper introduces a novel approach to enhancing the performance of large language models (LLMs) by leveraging an iterative process of self-feedback and refinement. Unlike traditional methods that rely on generating a single output or require additional training and external supervision, Self-Refine allows a model to critique and improve its own outputs through multiple iterations. By employing the same LLM as both the feedback provider and the refiner, this approach ensures that even state-of-the-art models, such as GPT-4, can produce higher-quality results across various tasks, ranging from dialogue generation to code optimization.
Research Gap
Self-Refine addresses a critical gap in the field of natural language processing by offering a method that improves model outputs without requiring extensive external supervision or additional training. Traditional approaches to refining LLM outputs often involve human-in-the-loop feedback, reinforcement learning, or domain-specific training data, all of which can be resource-intensive and challenging to scale. In contrast, Self-Refine’s uniqueness lies in its ability to perform iterative self-improvement within a single model, using a general framework that can be applied across various tasks. This self-contained, feedback-driven approach not only enhances the performance of LLMs but also paves the way for more autonomous and efficient AI systems in the future.
Solution: Self-Refine
The Self-Refine method is an approach designed to enhance the outputs of LLMs by using an iterative process of self-feedback and refinement. The key idea behind this method is to allow the LLM to generate an initial output, then provide feedback on that output, and finally refine it based on its own feedback. This cycle repeats until a desired level of quality is reached. The steps of Self-Refine method are as follows:
-
Initial Generation: Given an input, the LLM generates an initial output using a specific prompt designed for the task. This initial generation is the starting point for the refinement process.
-
Feedback Step: The LLM then provides feedback on its own output. This feedback is not just a general evaluation but is actionable and specific. The model is prompted to identify areas of improvement in its own output, which may include addressing issues like accuracy, coherence, relevance, or efficiency depending on the task.
-
Refinement Step: Using the feedback, the LLM refines its previous output. This step involves revising the initial output to improve its quality based on the feedback. The model uses a prompt that incorporates both the original input and the feedback to guide the refinement process.
-
Iteration: The feedback and refinement steps are repeated iteratively. The process continues until a stopping condition is met, which could be either a predefined number of iterations or the model’s own assessment that further refinement is unnecessary.
This is a self-contained process, since the entire method operates within a single LLM without requiring additional training data or external supervision. The same LLM serves as the generator, the feedback provider, and the refiner, making the method highly efficient and broadly applicable. The solution is also depicted in the following figure:
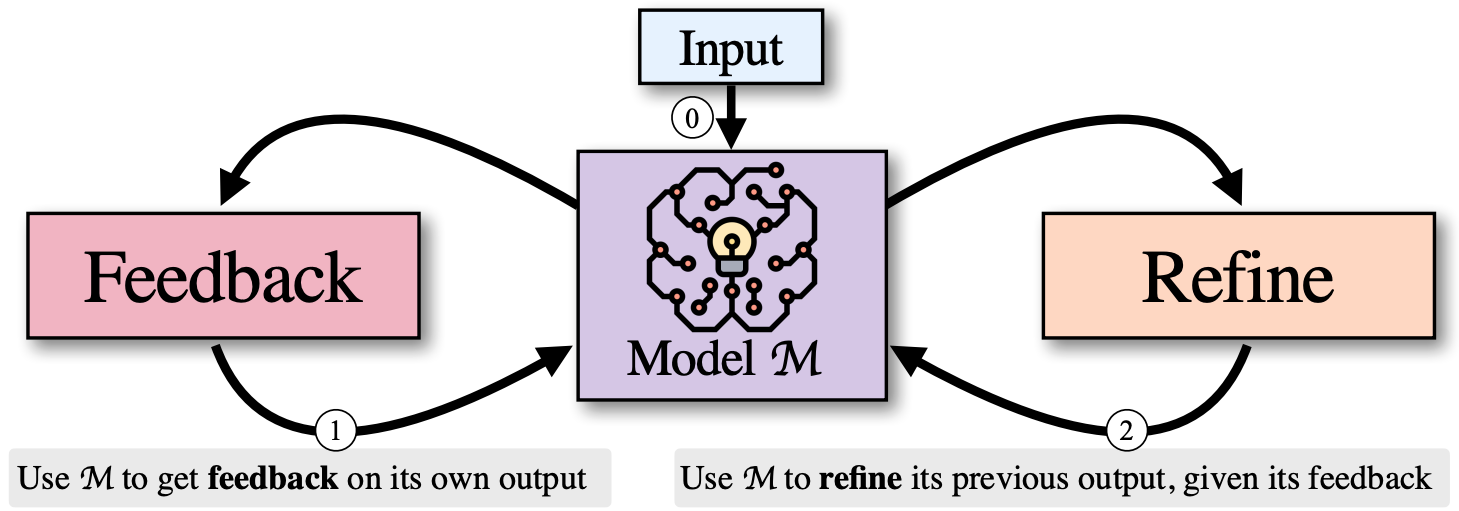
This approach allows even state-of-the-art models like GPT-4 to improve their outputs post-generation without needing any external interventions, relying solely on iterative self-feedback to enhance performance across various tasks.
Experiments
The authors evaluated the Self-Refine method across seven diverse tasks:
- Dialogue Response Generation
- Dataset: Based on the DialoGPT dataset.
- Task: Generate engaging and relevant conversational responses.
- Performance Measurement: Human preference ratings and GPT-4 preference scores were used since automated metrics are not easily applicable for this task.
- Feedback Generation: Feedback focused on making the response more relevant, engaging, and safe.
- Results: Self-Refine significantly improved the preference score, with GPT-4’s preference increasing by 49.2%.
- Code Optimization
- Dataset: 1000 Python programs sourced from the PIE dataset.
- Task: Improve the efficiency of Python code.
- Performance Measurement: Percentage of programs optimized (%OPT).
- Feedback Generation: Feedback included suggestions on improving time complexity and code efficiency.
- Results: Self-Refine improved the optimization rate by 8.7% on GPT-4 compared to the baseline.
- Code Readability Improvement
- Dataset: 300 programs, primarily sourced from the CodeNet dataset.
- Task: Refactor code to make it more readable.
- Performance Measurement: Human preference ratings and a GPT-4 evaluation focusing on the appropriateness of variable naming and code structure.
- Feedback Generation: Feedback centered on enhancing variable naming and adding comments to improve readability.
- Results: The method improved readability by 28.8% when using GPT-4.
- Math Reasoning
- Dataset: 1319 math problems from the GSM8K dataset.
- Task: Solve math word problems.
- Performance Measurement: Solve rate (% of correct solutions).
- Feedback Generation: Feedback aimed to ensure correctness by suggesting step-by-step solution approaches.
- Results: Modest improvements were observed, with a slight increase of 0.2% in solve rate for GPT-4.
- Sentiment Reversal
- Dataset: 1000 review passages from the Yelp dataset.
- Task: Reverse the sentiment of the given text (e.g., from positive to negative).
- Performance Measurement: Human preference and GPT-4 preference scores.
- Feedback Generation: Feedback focused on ensuring that the sentiment was adequately reversed and that the language used was consistent with the new sentiment.
- Results: Self-Refine showed substantial improvement, with a 32.4% increase in preference score using GPT-4.
- Acronym Generation
- Dataset: Custom dataset of 250 acronyms.
- Task: Generate meaningful acronyms for given phrases or titles.
- Performance Measurement: Human and GPT-4 preference scores, considering ease of pronunciation, spelling, and relevance to the title.
- Feedback Generation: Feedback was aimed at improving the relevance, ease of pronunciation, and overall suitability of the acronym.
- Results: Self-Refine led to a 25.6% improvement in preference score when using GPT-4.
- Constrained Generation
- Dataset: Custom dataset with 200 samples, an extension of the CommonGen dataset.
- Task: Generate sentences that include up to 30 given keywords while maintaining coherence.
- Performance Measurement: Coverage percentage of the included keywords and human/GPT-4 preference scores.
- Feedback Generation: Feedback focused on ensuring that all keywords were included and that the sentence remained coherent.
- Results: The model showed a 30% improvement in coverage and preference when using GPT-4.
Two examples scenarios are depicted in this figure:
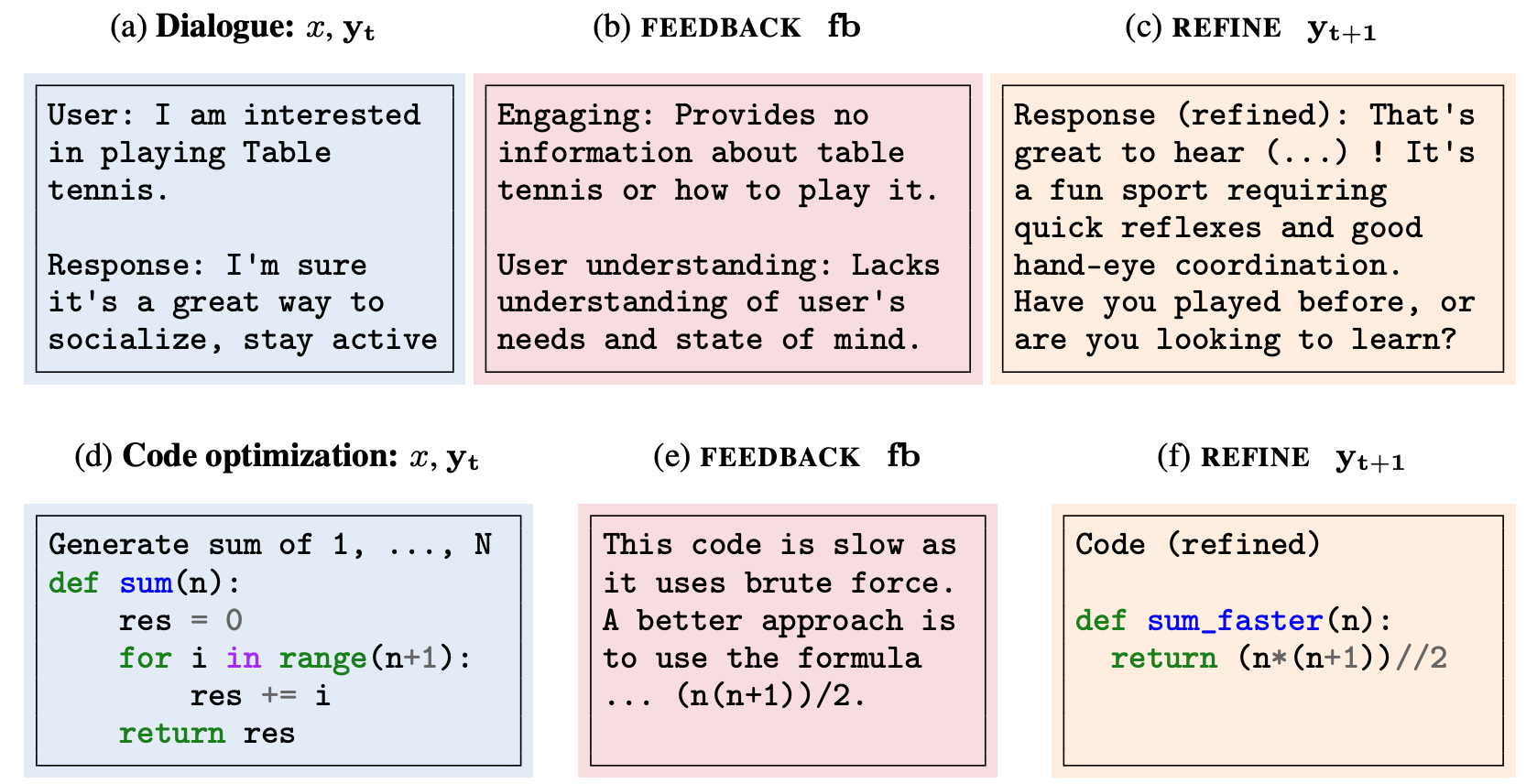
Across all tasks, Self-Refine consistently outperformed the baseline (direct generation without refinement) by significant margins. The quality and specificity of feedback were crucial to the success of the method. Specific, actionable feedback led to more significant improvements in the output compared to generic feedback or no feedback at all.
Conclusion
In summary, Self-Refine introduces an iterative approach to improving large language models by utilizing self-generated feedback to refine outputs. This method demonstrates effectiveness across a range of tasks, showing that models can improve their own results without the need for additional training. The results from applying Self-Refine suggest that this approach can enhance the quality of generated content in a variety of contexts, making it a practical tool for refining model outputs in natural language processing tasks.
SelfInstruct: Aligning Language Models with Self-Generated Instructions
SelfInstruct focuses on the automatic generation of instruction instances for training language models to follow instructions effectively. The paper introduces a pipeline for generating instructions and associated input-output samples.
Before we dive into the step-by-step details of the pipeline, let’s start by giving a broad overview of what this pipeline accomplishes overall. First of all, the dataset of instructions that is going to be generated and expanded in this work has three main attributes:
- Instruction: This is the natural language instruction that defines a specific task. It provides the context for the task that the language model needs to understand and follow.
- Input: This represents the input data or information required to perform the task described in the instruction. It can vary depending on the nature of the task and may include text, numbers, or other data.
- Output: This corresponds to the expected output or the desired result of the task.
Example:
Instruction: Write a summary of the SELF-INSTRUCT paper.
Input: The content of the SELF-INSTRUCT paper.
Output: A concise summary of the paper's content.
The objective of the SelfInstruct pipeline is to expand this dataset, emphasizing diversity. Importantly, this expansion does not involve generating new instructions. The instructions themselves remain unchanged. Instead, the focus is on expanding the associated input and output data for a given instruction, referred to as the target instruction. This process is called instance generation. It is worth mentioning that the instance generation process is carried out individually for each instruction, with each instruction serving as the target instruction in its respective round. Now, let us describe the steps of the SelfInstruct pipeline in details:
- Initialization with Human-Written Instructions: The first step involves initializing a task pool with a set of seed human-written instructions. In this case, they collect 175 human-written instructions, each corresponding to a specific task. This task pool serves as the starting point for generating a more extensive set of instructions. From this task pool, they sample 8 instructions for each iteration. Out of these 8 instructions, 6 are randomly selected from the original 175 human-written instructions (seed instructions), and the remaining 2 are sampled from model-generated instructions that were created in previous iterations.
- Instance Generation: The second step of the pipeline involves instance generation, where they create input-output pairs for the instructions. In this step, they employ two different approaches: the Input-first Approach and the Output-first Approach.
- Input-first Approach: As mentioned previously, in the instance generation step, the focus is on creating input-output pairs for a given target instruction. Accordingly, in the input-first approach, the goal is to generate instances for each instruction by first focusing on creating the input field based on the instruction. And then, the focus would be on creating the output field based on the instruction and the gerenated input. Here’s how it works:
- The pretrained language model is prompted with an instruction, and it is asked to generate the input fields for a specific task based on that instruction.
- The model interprets the instruction to understand what the task is, determines what additional input information is required, generates this input information, and then produces the corresponding output for that task.
- Essentially, the model generates the input and output sequentially, with the input being generated first. However, it’s mentioned that this approach might lead to inputs that are biased toward one label, especially for classification tasks. That is why they proposed the next approach for the instance generation.
- Output-first Approach: In contrast, the Output-first Approach is used primarily for classification tasks and is designed to address the issue of input bias. Here’s how it works:
- For classification tasks, the model first generates the possible class labels for the task. These class labels represent the different categories or options that the output could belong to.
- Once the class labels are generated, the model then generates the input for the task, conditioning it on each of the class labels. This approach ensures that the input is not biased toward a single label, making it more suitable for classification-type tasks.
- Input-first Approach: As mentioned previously, in the instance generation step, the focus is on creating input-output pairs for a given target instruction. Accordingly, in the input-first approach, the goal is to generate instances for each instruction by first focusing on creating the input field based on the instruction. And then, the focus would be on creating the output field based on the instruction and the gerenated input. Here’s how it works:
- Filtering and Quality Control: The generated instances–the target instruction and the generated input and output–are passed through a filtering step to ensure diversity and quality of the generated instances. A filtering criteria could the the similarity of the genereated instance and the existing instances. If the similarity score–which can be measured by different metrics, such as ROUGE-L, is above a specific threshold, then the generated instance is considered to have a very low quality and will be excluded from the final dataset.
For evaluation, they use their generated dataset in order to finetune GPT-3, called GPT3selfIns. Then, they use the SuperNaturalInstractions framework–which is a large collection of tasks and their textual instructions for measuring the performance of their model. GPT3selfIns outperforms GPT-3 by a large margin. However, it is still comparable (or even slightly behind) InstructGPT model.
Here are some more articles relevant to this one: