Paper Review - Week 23
Here is the list of the most interesting papers published in this week:
PALR: Personalization Aware LLMs for Recommendation
Introduction
his paper introduces a novel framework, PALR (Personalization Aware LLM for Recommendation), designed to integrate user historical behaviors with LLMs for more personalized and accurate item recommendations. Recognizing the challenges of incomplete knowledge representation and the limitations posed by extensive item pools, PALR addresses these issues through a multi-step approach, incorporating user profile summarization, candidate retrieval, and LLM-based recommendation generation. By fine-tuning the LLaMa 7B model and employing instruction-based techniques, PALR demonstrates its potential to enhance the reasoning capabilities of LLMs and provide more precise and relevant recommendations in various sequential recommendation tasks.
Research Gap
The primary focus of the authors is to develop a personalized recommendation system leveraging LLMs while addressing the specific challenges commonly associated with such systems. The challenges which are the main focus of PALR are:
- Newly-added Items: The concern here is that newly added items to the recommendation system might not be represented in the LLM’s knowledge. This can result in the system being unable to make accurate recommendations for these newly-added items.
- Incomplete or Hallucinatory Results: LLMs can sometimes generate incomplete or even imaginary results, commonly referred to as the hallucination problem. This issue can lead to the inclusion of irrelevant or nonsensical recommendations, which undermines the trust and credibility of the recommendation system.
- Token Limitations: LLMs typically have restrictions on the number of tokens that can be included in their inputs. This token limitation can be a challenge, especially in the context of recommendation systems where the item pool may be extensive.
Solution: PALR
The main architecture of PALR is as follows:
- User Profile Summarization (using LLMs): The initial step involves feeding the user’s interaction history into an LLM to generate a summary of the user profile. This step aims to capture the user’s preferences and interests, which are then used to guide the recommendation process. By producing a concise representation of the user’s preferences, the system can better understand the user’s needs and tailor the recommendations accordingly.
- Retrieval System for Filtering Items: The retrieval system receives information about the user’s target task and their profile. It then filters the item pool to remove or filter out irrelevant items. As far as I know, the specific metrics used for filtering the items are explicitly mentioned in the paper, but they are likely based on relevance to the user’s preferences, historical interactions, or task-specific criteria. This step is crucial for managing the inclusion of newly-added items in the recommendation system and ensuring that the recommendations remain relevant and up-to-date.
- LLM-based Recommendation Generation: Then, another LLM is employed to generate the final recommendations based on a designed prompt. The designed prompt is created using the summarized user profile and the retrieved items. To be more specific, the designed prompt includes a task instruction, an output template, the summarized user profile, the user interaction history, and the retrieved items as candidate items for recommendations. By utilizing this LLM for recommendation generation, the framework leverages the model’s reasoning capabilities to provide accurate and personalized recommendations to the users.
The following figure is an overview of the architecture:
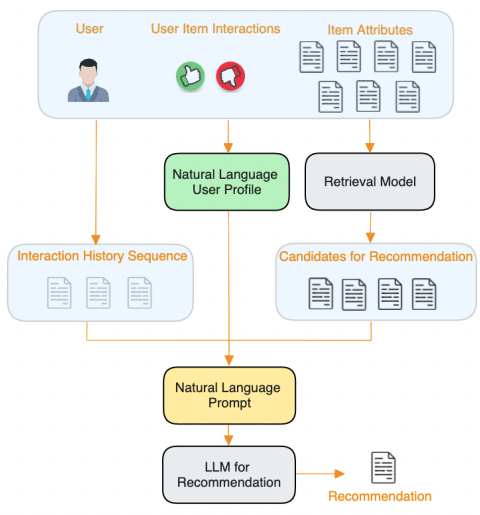
Also, here is a sample of prompts used for extracting user profile summary and recommendation items according to the user profiles.

Personal Comment: It is not clear if the LLM used in the user profile summerization and the one used in recommendation generation are two distinct LLMs or are the same. However, the authors mention that for the recommendation generation step, they leveraged LLaMa 7B model.
Another important point is that the authors mention that fine-tuning the model has a significant effect in personalising the recommendation system. Specifically, they fine-tune the LLaMa 7B model to better adapt it for the recommendation scenario. The fine-tuning process involves incorporating instruction-based fine-tuning techniques. The fine-tuning process is as follows:
- Instruction Tasks: The authors create two types of instruction tasks, namely Recommend and Recommend_Retrieval, to guide the fine-tuning process. These tasks involve providing the model with specific instructions on generating recommendations based on a user’s historical interactions and the candidate items for recommendation.
- Retrieval Layer Agnostic: The fine-tuning process is not dependent on any specific retrieval layer within their framework. Despite training the model to select items from a list of candidates, the construction of this list during the fine-tuning process is not tied to the retrieval layer, ensuring the flexibility and adaptability of the framework.
Experiments
The primary aspects of the experimental setups are as follows:
- Datasets: The experiments were conducted on: (1) MovieLens-1M dataset, which contains 1 million ratings from 6000 users for 4000 movies; and (2) Amazon Beauty dataset, which is a real-world dataset from Amazon containing user-item interactions on beauty products.
- Baselines: The authors compare PALR with several baselines including: BPR-MF (Bayesian Personalized Ranking with Matrix Factorization), NCF (Neural Collaborative Filtering), GRU4Rec, Caser, and SASRec.
- Evaluation Metrics: The evaluation metrics used in the experiments are HR and NDCG.
- Results: The results indicate that the PALR framework outperforms the various baseline models by a substantial margin on both the Amazon Beauty and Movielens-1M datasets. The comparisons highlight the significance of incorporating a retrieval module and fine-tuning process in the PALR framework, leading to more accurate and relevant recommendations.
Conclusion
In conclusion, this paper presents PALR as a promising framework that effectively combines the power of large language models with user historical behaviors to improve the accuracy and personalization of recommendation systems. By addressing the challenges of incomplete knowledge representation and token limitations within LLMs, PALR demonstrates its robustness and effectiveness in generating more relevant and contextually accurate recommendations for users.
Here are some more articles relevant to this one: