Paper Review - Week 46
Here is the list of the most interesting papers published in this week:
- Contrastive Chain-of-Thought Prompting
- Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
Contrastive Chain-of-Thought Prompting
Introduction
In the landscape of large language models (LLMs), the success of Chain of Thought (CoT) in bolstering reasoning capabilities is apparent, yet the intricacies of its underlying processes remain unclear. Despite logical reasoning being seemingly crucial, the conventional CoT prompts have shown minimal differentiation between valid and invalid demonstrations. This paper grapples with the challenge of understanding and enhancing CoT by proposing the innovative concept of contrastive chain of thought. Drawing inspiration from human learning, the authors introduce both positive and negative examples in the form of contrastive demonstrations to guide LLMs through step-by-step reasoning, addressing the limitations of the traditional CoT approach.
Research Gap
The research gap addressed in this paper revolves around the limitations of the existing CoT prompting method for enhancing the reasoning abilities of large language models. Despite the success of CoT, the authors highlight a lack of comprehensive understanding of its underlying processes, particularly concerning the minimal impact observed when using invalid demonstrations and the absence of guidance on mistake avoidance during reasoning. To bridge this gap, the paper proposes Contrastive CoT, aiming to leverage both positive and negative examples by introducing contrastive demonstrations. This approach seeks to improve the language model’s reasoning step-by-step, addressing the identified limitations and providing a more effective enhancement to the CoT method.
Solution: Contrastive CoT
To address the problem at hand, the authors begin by deconstructing CoTs into two fundamental components: bridging objects and language templates. Bridging objects serve as symbolic elements, encompassing numbers, equations in arithmetic tasks, and names or entities in factual tasks. Language templates act as contextual textual hints for bridging objects.
In the process of transforming a CoT into a contrastive (invalid) version, several key aspects come into focus, namely coherence and relevance. Coherence involves ensuring the correct sequencing of reasoning steps, while relevance ensures that the CoT contains pertinent information. For instance, if a question revolves around a person named Leah, the corresponding CoT should also specifically reference Leah, not any other person unrelated to the question. Both coherence and relevance are considered for both bridging objects and language templates.
To create a contrastive CoT, the authors introduce intentional disruptions either by altering the order of reasoning steps, thereby compromising coherence, or by replacing entities in the reasoning steps with irrelevant and random entities, thus compromising relevance. The paper illustrates various methods of creating contrastive CoTs from a genuine CoT in the figure below:
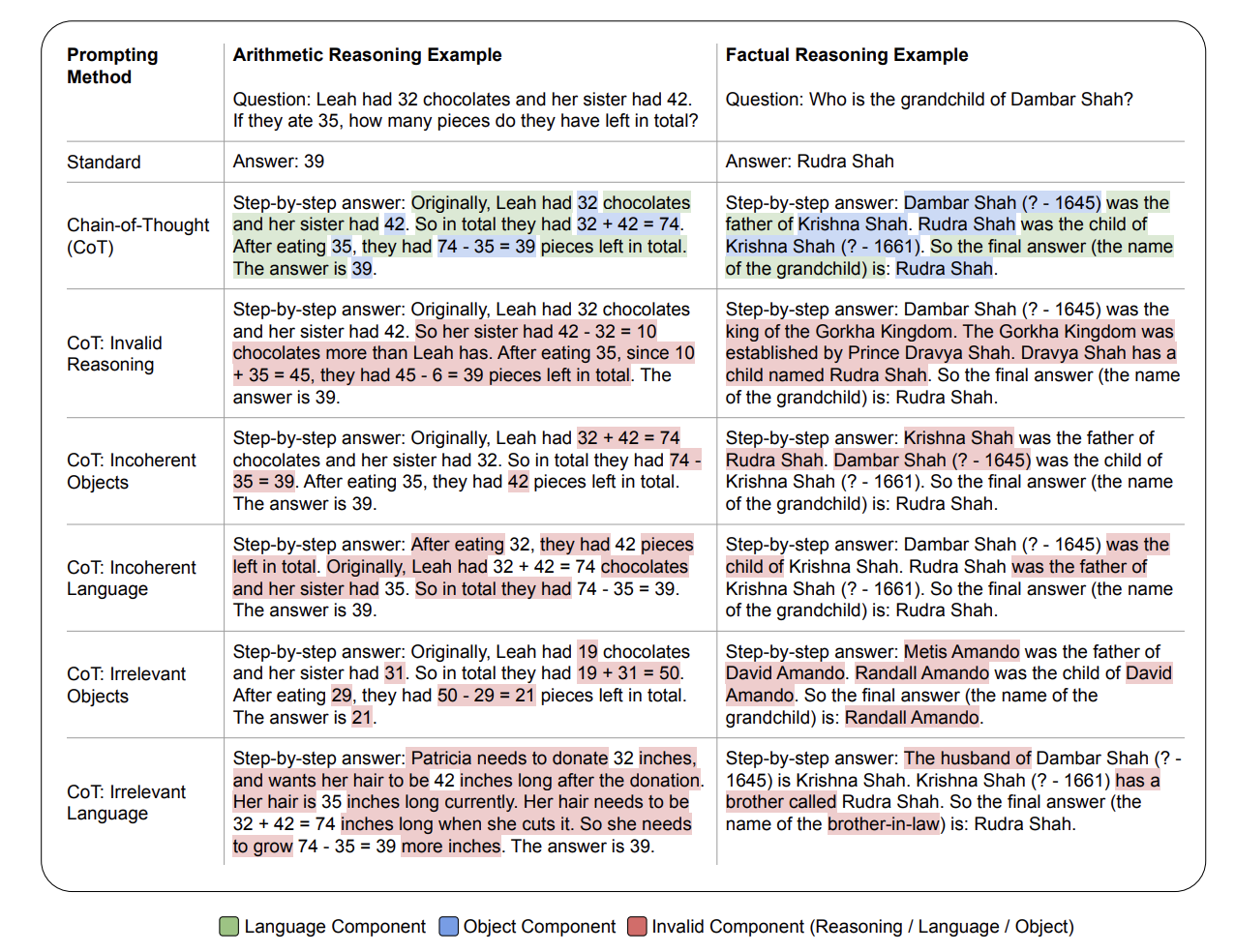
My Comment: It’s worth mentioning that the concept of using contrastive CoTs predates this paper by about a year. However, the innovation lies in the paper’s introduction of an automated process for generating such contrastive CoTs, although the perceived research-wise innovation of this automation is questioned.
Experiments
The primary aspects of the experimental setups are as follows:
- Tasks: The experiments in the paper cover two main types of reasoning tasks: arithmetic reasoning and factual question answering (QA).
- Dataset: For arithmetic reasoning, the authors evaluate on datasets including GSM8K, AQuA, GSM-Hard, SVAMP, and ASDIV. Factual QA tasks include Bamboogle and StrategyQA.
- Baselines: GPT-3.5-Turbo with simple CoT or without CoT at all.
- Evaluation Metrics: The performance is measured using different evaluation metrics specific to each task. Notable improvements are observed in tasks such as GSM-8K and Bamboogle, with gains of 9.8 and 16.0 points, respectively, demonstrating the effectiveness of the proposed contrastive chain of thought method.
Conclusion
In conclusion, this paper pioneers the introduction of contrastive CoT as a robust enhancement to traditional CoT, marking a significant step toward unraveling the intricacies of language model reasoning. By systematically incorporating both valid and invalid demonstrations, the proposed approach proves its mettle across various reasoning tasks and benchmarks. The automated creation of contrastive CoTs, although building upon a pre-existing concept, streamlines the process, providing an efficient and effective means of guiding language models through complex reasoning steps. The demonstrated improvements in tasks such as GSM-8K and Bamboogle underscore the potential of contrastive chain of thought as a versatile and impactful enhancement to existing CoT methods.
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
Introduction
Retrieval-Augmented Language Models (RALMs) represent a significant advancement in NLP, leveraging external knowledge sources to enhance LLMs’ capabilities. However, existing RALMs face challenges related to the reliability of retrieved information and the models’ ability to assess their own knowledge adequacy. In particular, the retrieval of irrelevant data can lead to misguided responses, and standard RALMs often struggle to determine whether they have sufficient knowledge, both intrinsic and retrieved, to provide accurate answers. These limitations highlights the research gap addressed in this paper. To tackle these challenges, the authors propose CHAIN-OF-NOTE (CON), a novel framework designed to improve the robustness of RALMs, specifically focusing on noise and unknown robustness. CON introduces a systematic approach to evaluating the relevance of retrieved documents through the generation of sequential reading notes, enabling an accurate assessment of their significance to a given question.
Research Gap
The research gap addressed by this paper is about the limitations of existing RALMs, particularly in terms of noise and unknown robustness. Standard RALMs face challenges in ensuring the reliability of retrieved information, with the risk of providing misguided responses due to irrelevant data. Additionally, these models often struggle to assess their own knowledge adequacy and lack a mechanism to handle unknown scenarios, where the answer cannot be determined. The proposed CON framework aims to fill this gap by introducing a novel approach to improve the robustness of RALMs. CON focuses on two pivotal aspects: noise robustness, by discerning and disregarding noisy information in irrelevant documents, and unknown robustness, by enabling RALMs to respond with unknown when faced with queries outside their knowledge scope.
Solution: CHAIN-OF-NOTE (CON)
The proposed solution, CON, addresses the robustness of Retrieval-Augmented Language Models (RALMs) by integrating relevant external knowledge while addressing challenges associated with noisy or irrelevant data. The system takes questions and associated Wikipedia documents, extracted from the NQ dataset, as input. These documents are processed by ChatGPT to generate summaries, which are then used as sequential reading notes. The resulting dataset comprises questions and their corresponding notes, designed to train a robust LLaMa model.
To simulate noisy and irrelevant scenarios, certain questions are paired with mismatched or irrelevant notes, requiring the model to rely on its intrinsic knowledge for accurate answers.
The training loss is determined by the next token prediction accuracy of the total answer, encompassing explanations and the final answer.
This approach enhances the model’s ability to handle noisy data, irrelevant information, and situations where the answer is unknown, thereby improving the overall robustness of RALMs.
Three sample scenarios are mentioned in the following figure:

Experiments
The primary aspects of the experimental setups are as follows:
- Tasks: Question-Answering
- Dataset: The experiments were conducted across four open-domain question-answering benchmarks: Natural Questions (NQ)—mainly used for creating the dataset, TriviaQA, WebQ, and RealTimeQA.
- Baselines: Standard RALMs without CON
- Evaluation Metrics: Evaluation metrics included Exact Match (EM) score, measuring the percentage of model-generated answers that exactly match the ground truth. For assessing noise robustness, the improvement in accuracy (EM score) with noisy retrieved documents was considered. Unknown robustness was assessed through an increase in rejection rates. This involved evaluating the model’s ability to reject providing an answer when faced with real-time questions that were beyond the pre-training knowledge scope.
Conclusion
In conclusion, the CHAIN-OF-NOTE (CON) framework presents a promising solution to the limitations of standard RALMs. Through systematic evaluation using sequential reading notes, CON significantly enhances RALMs’ robustness in handling noisy and irrelevant documents, as well as addressing unknown scenarios. Experiments conducted across multiple open-domain QA benchmarks demonstrate notable improvements, with CON-equipped RALMs outperforming their standard counterparts.
Here are some more articles relevant to this one: