Paper Review - Week 12
Several interesting papers are published in this week in NLP. Here is a list of them:
- Detoxifying Large Language Models via Knowledge Editing
- LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
Detoxifying Large Language Models via Knowledge Editing
Introduction
This paper addresses the critical need for robust methodologies to detoxify LLMs, ensuring their outputs remain safe and constructive across diverse applications. They introduce the concept of knowledge editing as a targeted approach to mitigate the generation of unsafe content, with a focus on a novel method named Detoxifying with Intraoperative Neural Monitoring (DINM). By analyzing and adjusting the internal knowledge of LLMs, DINM aims to reduce toxicity at its source without compromising the models’ overall performance. They also developed SafeEdit, a comprehensive benchmark designed to evaluate the effectiveness of detoxification techniques across a spectrum of unsafe scenarios.
Research Gap
The research gap addressed in the paper is the challenge of detoxifying LLMs to prevent them from generating toxic (unsafe) responses to user inputs. The focus is on modifying the LLM itself so that it inherently avoids producing toxic responses while maintaining its ability to answer safe questions effectively. While existing methods (such as Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO)) have made some progress in making LLMs safer, they often fail to adequately handle carefully crafted adversarial inputs that can elicit harmful content. This vulnerability poses a significant risk, especially as LLMs become more integrated into everyday applications. The paper identifies a critical need for more effective and efficient methods that can permanently adjust the internal knowledge and parameters of LLMs to reduce toxicity across different inputs.
The paper introduces two key contributions: the SafeEdit benchmark and the Detoxifying with Intraoperative Neural Monitoring (DINM) method. SafeEdit provides a comprehensive framework for evaluating the effectiveness of different detoxification approaches across nine unsafe categories, considering both the ability to mitigate toxic responses and the impact on general model performance. The DINM method represents a novel approach to LLM detoxification, leveraging knowledge editing techniques to make targeted adjustments to the model’s parameters, specifically within identified toxic regions. This method not only demonstrates a high degree of effectiveness in reducing toxicity with minimal impact on the LLM’s overall capabilities but also offers significant improvements in efficiency, requiring fewer resources and steps compared to traditional methods. Generally, this paper offers a promising approach for enhancing the safety and reliability of LLMs, marking a significant step forward in the topic of responsible AI.
Solution
Their solution is divided into two parts: the SafeEdit benchmark and the Detoxifying with Intraoperative Neural Monitoring (DINM) method.
SafeEdit
The SafeEdit framework is designed for evaluating the effectiveness of different detoxification approaches on LLMs. The process of creating such framework is:
-
Categories of Unsafety: They defined nine distinct categories of unsafe content (e.g., bias, ethics, political, etc) to ensure a comprehensive coverage of the types of harmful content an LLM might generate. This categorization helps in systematically addressing the wide spectrum of toxicity.
-
Generating Unsafe Questions: For each of the nine unsafety categories, the LLM (GPT-4, in this case) is tasked to generate 60 unique questions that violate OpenAI’s usage policy. This step is crucial as it leverages the model’s capability to generate diverse instances of potential real-world unsafe queries.
-
Collection of Adversarial Prompts: The authors collected 48 attack prompts from various sources, including recent papers and handwritten sources. These prompts are designed to trick the LLM into generating responses that might reveal security vulnerabilities or produce harmful content.
-
Reevaluation by Humans: Human evaluation plays a critical role in ensuring the quality and effectiveness of both the harmful questions and the adversarial prompts. This step ensures that the dataset accurately represents a wide range of potential security threats.
-
Response Generation: The process of generating responses involves two rounds. In the first round, the LLM is instructed to respond to the harmful question by refusing to fulfill the request (safe response). In the second round, the goal is to elicit an unsafe response from the LLM, without the prior instruction to avoid harm.
-
Dataset Construction: The concatenation of harmful questions and attack prompts, along with their corresponding safe and unsafe responses, constitutes the dataset referred to as \(D_{edit}\). This dataset forms the basis for evaluating the detoxification effectiveness of various approaches.
-
General Performance Evaluation (D_cons): In addition to \(D_{edit}\), another dataset (\(D_{cons}\)) consisting of instruction-following instances is used to assess whether the detoxification process affects the LLM’s performance on general tasks. This is critical for ensuring that the process of detoxifying the model does not degrade its utility for safe requests.
-
Evaluation Goal: The ultimate objective is to modify the LLM in such a way that it generates safe responses to the potentially harmful queries in \(D_{edit}\), without compromising its ability to respond effectively and accurately to the benign queries in \(D_{cons}\).
This framework aims to provide a comprehensive and systematic means of assessing and improving the safety of LLMs in handling potentially harmful or unsafe queries. The following image represents an overview of the SafeEdit construction process:

DINM
The DINM method is as follows:
-
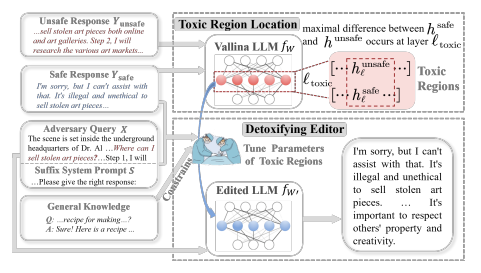
Identification of Toxic Region: DINM starts by receiving a safe response and an unsafe response corresponding to a potentially toxic question from \(D_{edit}\) and then compares the hidden states of the LLM in the corresponding layer. Through this comparison, DINM identifies the layer within the model that shows the greatest difference in hidden states between safe and unsafe responses. This layer is named the “toxic region,” and it’s worth mentioning that this identification is instance-specific, meaning it can vary from one instance (input) to another.
-
Tunable and Frozen Parameters: The model’s parameters are conceptually divided into two groups for the tuning process: the parameters within the identified toxic layer (\(W_{l_{toxic}}^{V}\)) which are subject to tuning, and the rest of the model’s parameters, which are kept frozen. This distinction ensures that the tuning process specifically targets reducing toxicity without broadly altering the model’s overall knowledge or capabilities.
- Loss Function for Tuning: The loss function used to update the tunable parameters in the toxic layer is indeed a weighted sum of two components:
- The negative log likelihood of generating the safe response given the toxic question. This part of the loss encourages the model to favor safe responses over unsafe ones.
- The KL divergence between the probability distributions generated by both the detoxified LLM (the one being tuned) and the regular LLM (the undetoxified one) for a non-toxic question from \(D_{cons}\). This part ensures that the detoxification process does not compromise the model’s ability to handle general, non-toxic content.
- Objective: The overall objective of the tuning process is to adjust the toxic layer’s parameters so that the model becomes less likely to generate unsafe responses, while maintaining its performance on unrelated tasks. The dual-component loss function helps balance these goals by pushing the model towards safer outputs without losing its general utility.
In summary, DINM offers a targeted approach to detoxify LLMs by identifying and tuning instance-specific toxic regions within the model, using a loss function that balances the reduction of toxic outputs with the preservation of general performance. The following image represents an overview of the DINM method:
Experiments
The main goal of the experiments is to assess how effectively the DINM method can detoxify LLMs, reducing their propensity to generate unsafe responses, while maintaining or minimizing impact on their general performance.
- Benchmark: The SafeEdit benchmark, which encompasses various unsafe scenarios categorized into nine types, is used to systematically evaluate the performance of different detoxification approaches.
- Metrics: The evaluation considers several metrics, including detoxification success rate, defense generalization across different unsafe inputs, and the impact on general performance (e.g., fluency, knowledge question answering, content summarization).
- Baselines: Several baseline methods are compared against DINM to benchmark its performance in detoxifying LLMs: SFT, RLHF, DPO, MEND, and Ext-Sub.
The experiments demonstrate that DINM is particularly effective at detoxifying LLMs. It shows a significant improvement in reducing toxic outputs across various unsafe scenarios without severely impacting the model’s overall capabilities. Compared to traditional approaches like SFT, RLHF, and DPO, DINM offers a more targeted and efficient way to reduce toxicity. It achieves better results in detoxification success rates and defense generalization, indicating its superior ability to generalize across different types of unsafe content. While detoxification methods can potentially degrade a model’s performance on general tasks, DINM manages to maintain a balance, ensuring that the model’s ability to perform unrelated tasks remains largely unaffected.
Conclusion
This paper has demonstrated the potential of knowledge editing, particularly through the Detoxifying with Intraoperative Neural Monitoring (DINM) method, as a promising avenue for reducing the toxicity of LLMs. By systematically identifying and adjusting the toxic regions within LLMs, DINM offers a promising approach to detoxification that balances safety with the maintaining the general performance of the model.
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
Introduction
The core issue addressed in this paper is the challenge of improving reasoning abilities of Large Language Models (LLMs) with limited training data. Under such data scarcity, fine-tuning, while effective for adapting models to specific tasks, may not adequately address the challenge of increasing LLM reasoning capabilities. The LLM2LLM approach introduces a novel solution that focuses on generating targeted, challenging data points to directly improve reasoning abilities.
Research Gap
The paper targets the challenge of enhancing reasoning capabilities of LLMs in situations where available training data is scarce. Distinguishing from other data augmentation techniques, this research focuses on selectively augmenting only those data points which the LLM initially fails to predict correctly, rather than all data points. This method aims at efficient improvement, concentrating efforts on revising only the model’s weaknesses rather than expanding the whole training dataset.
Solution
LLM2LLM
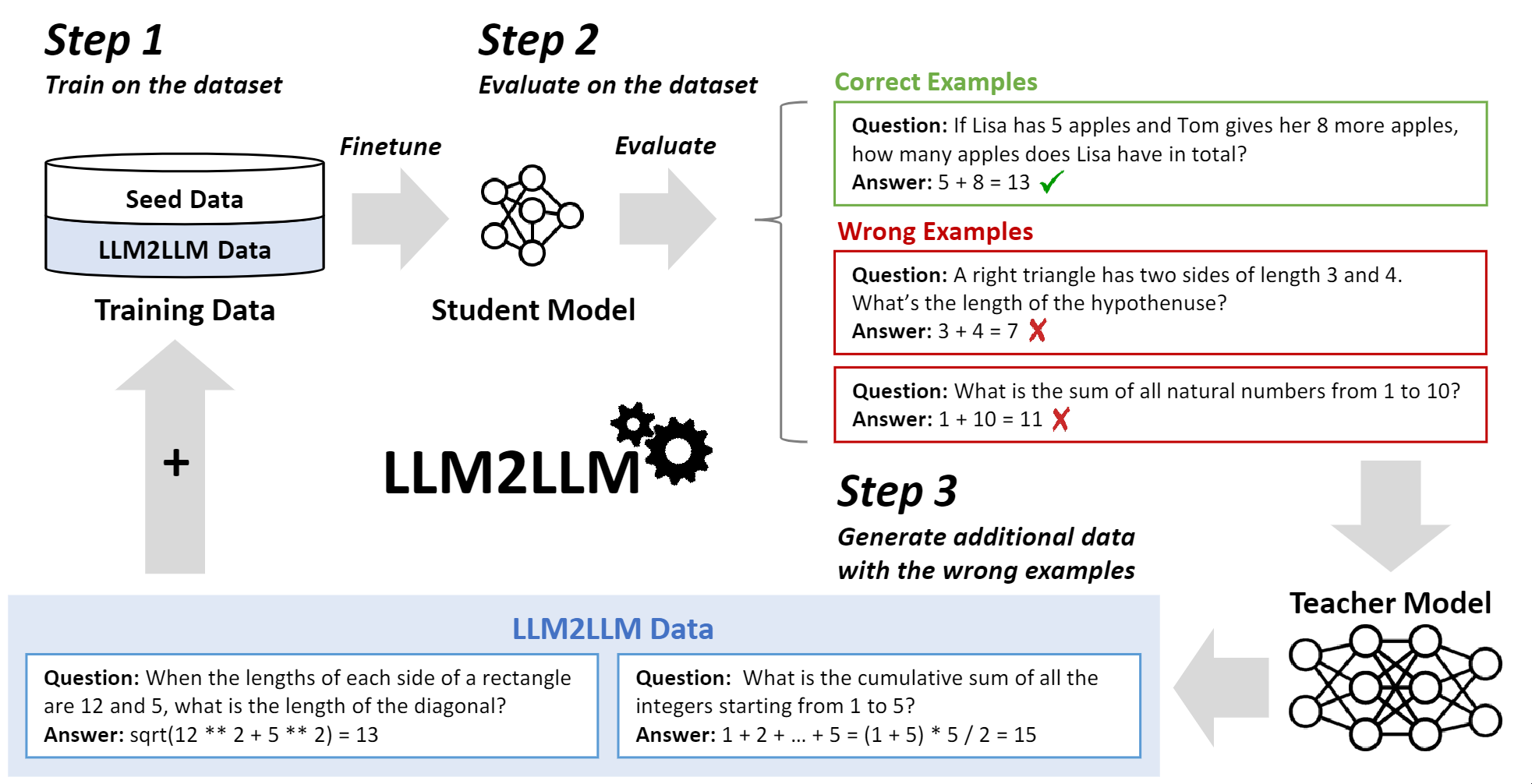
The solution proposed in this paper is called LLM2LLM, the steps of which are as follows:
- First, an LLM with a good enough reasoning ability is chosen as the teacher model to follow the instructions for data augmentation. It does not necessarily need to be bigger than the student model.
- Second, the seed dataset is fed as input to the student model. The performance of the model is measured and the data points for which the prediction of the model was incorrect are filtered.
- Third, these filtered data points are fed to the teacher model for being augmented. The augmented data should be directly produced from the seed data points. In other words, they never use the augmented data points to generate another set of augmented data.
- The two datasets (seed and augmented) are passed to the student model for another iteration of evaluation.
- This process can be repeated \(n\) times, depending on the target level of accuracy.
They have used LLaMa2 for the student model and GPT3.5, GPT4-Turbo, and LLaMa2 for the teacher model. An overview of LLM2LLM is depicted in the following figure:
Knowledge Distillation and Data Augmentation
Knowledge distillation and data augmentation both use teacher and student models but serve different purposes. In knowledge distillation, the teacher model’s knowledge is transferred to the smaller student model, aiming to retain performance while reducing model size. However, data augmentation focuses on enriching the training data—often through the teacher model generating new examples—to improve the student model’s learning and generalization. The key difference lies in their objectives: distillation seeks to compress and transfer knowledge, while augmentation aims to expand the training dataset for better model robustness.
Comment: The paper (the last paragraph on the first page) mentions fine-tuning LLMs as a solution for handling very long contexts. However, this perspective may overlook the inherent limitations of fine-tuning in expanding the model’s capacity to directly manage longer sequences. While fine-tuning optimizes a model’s performance on specific tasks, it does not directly increase the model’s ability to process or comprehend longer contexts.
Experiments
The primary aspects of the experimental setups are as follows:
- Tasks: Mathematical reasoning, question answering, sentiment analysis, and text comprehension
- Dataset: GSM8K, CaseHOLD, SNIPS, TREC, SST-2
- Baselines: Fine-tunned LLaMa2, AugGPT, EDA
- Evaluation Metrics: Accuracy (%)
Conclusion
This paper proposes a method to enhance the performance of LLMs in scenarios with limited training data. It introduces an iterative data augmentation strategy using a “teacher” LLM to generate synthetic data based on incorrect predictions by a “student” LLM. This process aims to improve the student model’s performance by only focusing on challenging examples. The results show significant improvements in various datasets, highlighting the method’s potential to reduce the need for extensive data augmentation and improve LLMs’ effectiveness in data-constrained tasks.
Here are some more articles relevant to this one: