Paper Review - Week 41
Here is the list of the most interesting papers published in this week:
Prompt Distillation for Efficient LLM-based Recommendation
Introduction
The paper presents an novel approach to multi-task recommendation systems, aiming to train a single model that handles various recommendation tasks, including sequence recommendation, top-N recommendation, and explanation generation. Leveraging a novel prompt distillation technique, the study formulates these recommendation tasks as text generation challenges, effectively transforming them into a unified framework. The proposed method entails the extraction of continuous prompts from discrete prompts, which are both task and sample-specific, enabling the integration of tailored prompts into a single LLM. They conducted comprehensive experiments and compared their system (POD) with state-of-the-art baselines on three Amazon datasets. The study shows the effectiveness of the proposed method in enhancing recommendation accuracy and generating coherent explanations.
Research Gap
The research gap that the authors are addressing revolves around the limitations of integrating LLMs into recommendation systems, particularly with respect to handling user and item IDs in the context of the textual data processed by LLMs. They specifically focus on the following challenges:
-
Efficiency in Processing Long Texts: The authors emphasize that the input to LLM-based recommendation models is often long and may contain noisy information, making the processing time-consuming and inefficient, especially for tasks that require immediate responses.
-
Fine-tuning and Bridging the Gap: LLMs typically require extensive fine-tuning to bridge the gap between user/item IDs and the template words, hindering their full potential for recommendation tasks.
-
Inference Efficiency: While they successfully improve the training efficiency, the authors note that enhancing the inference efficiency of LLM-based recommendation models remains a challenging issue.
The proposed PrOmpt Distillation (POD) approach aims to address these issues by distilling discrete prompts into continuous prompt vectors, which can reduce the inference time and improve the overall efficiency of LLM-based recommendation models. By focusing on this prompt distillation technique and proposing a task-alternated training strategy, the authors seek to enhance the performance of LLMs in the context of various recommendation tasks.
Solution: POD
The solution is based on training a unified model for diverse recommendation tasks by reframing these tasks as text generation problems. It covers a range of tasks including sequence recommendation, top-N recommendation, and explanation tasks.
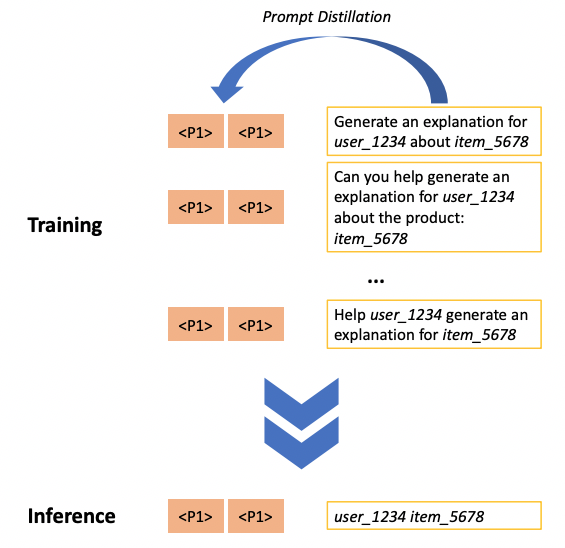
The key technique employed is prompt distillation, which aims to shorten lengthy prompts without compromising the performance of the underlying language model on various test tasks. This process results in the generation of concise prompts, either in the form of free text or vectors.
In this paper, prompt distillation involves the identification of effective continuous prompts from discrete prompts. These continuous prompts are fine-tuned for each task but remain consistent across samples within the same task. On the other hand, discrete prompts are specific to each sample and are created by combining user IDs and item IDs.
The continuous prompts are appended to the input sequence before the discrete prompts and are treated as trainable components that are part of the model parameters. The entire model is updated using the Negative Log Likelihood loss function, which is well-suited for generation tasks.
The following image represents the input sequence for a specific task during the training time.
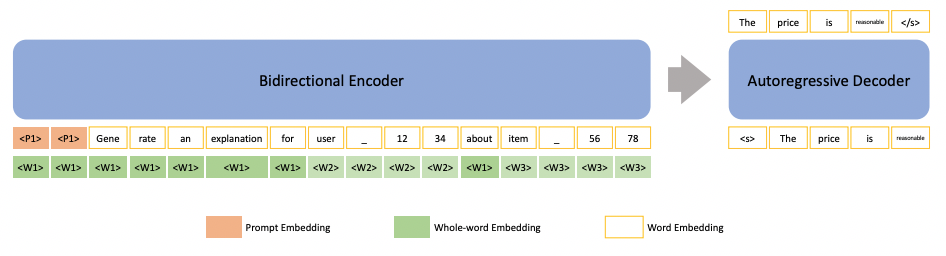
As it is illustrated, P1 is the task-specific continuous prompt. After the training phase, when the continuous prompt is tuned, the entire prompt “Generate an explanation for …. about item ….” is substituted with the tuned continuous prompts—as is depicted in the following figure:
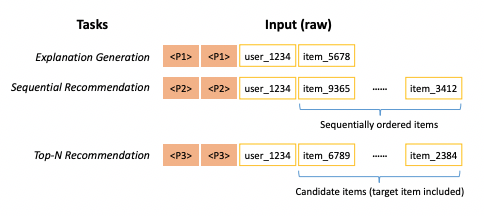
So, generally, the input sequence format in training and inference time can be represented as:
Experiments
The experimental setup involved the use of three popular datasets sourced from Amazon, namely Sports & Outdoors, Beauty, and Toys & Games, each containing specific user IDs, item IDs, ratings, textual reviews, and timestamps. The datasets were divided into training, validation, and testing sets.
For the sequential recommendation task, the experiment employed a range of baselines such as CASER, HGN, GRU4Rec, BERT4Rec, FDSA, SASRec, and S3-Rec. Additionally, for the top-N recommendation task, baselines included MF, MLP, and P5. Lastly, for the explanation generation task, models like Att2Seq, NRT, and PETER were used for comparison.
The evaluation metrics utilized were Hit Ratio (HR), Normalized Discounted Cumulative Gain (NDCG) for sequential and top-N recommendation, and BLEU and ROUGE for generated explanations. The study was conducted using the T5-small model as the backbone, employing the AdamW optimizer, with specific hyperparameters and checkpoints set for the training and evaluation phases. Beam search with specific parameters was used for inference.
Conclusion
In conclusion, the paper introduces a novel framework for multi-task recommendation systems, demonstrating the efficacy of prompt distillation in training a single model for various recommendation tasks. By leveraging task-specific and sample-specific prompts, the proposed method achieves improved recommendation accuracy and generates coherent explanations, as evidenced by extensive experiments on diverse Amazon datasets. The study’s findings highlight the potential of leveraging text generation approaches within the recommendation domain and pave the way for further advancements in unified recommendation systems.
Here are some more articles relevant to this one: